ChatGPT는 어떻게 연구자의 질문을 이해하고 답을 할 수 있을까?


AI agent란 무엇인가?
ChatGPT 사용해 보셨나요? 하이퍼랩 블로그에서도 ChatGPT, Gemini 등 여러 LLM을 다룬 바 있습니다. 오늘은 단순한 형태의 질의에 답하는 챗봇을 넘어, 보다 복잡한 태스크를 수행할 수 있는 AI 에이전트와 그 사용 예시에 대해 설명드리겠습니다. AI 에이전트는 사용자의 지시문을 이해하고, 이를 달성하기 위한 계획을 수립한 뒤 실행하는 과정을 반복합니다.
놀랍게도, AI 에이전트는 단순한 질문에 대한 답변을 생성하는 데 그치지 않고, 문제 해결을 위한 계획을 수립합니다. AI 에이전트에서 LLM은 매우 핵심적인 역할을 하며, 사용자의 지시문 이해, 계획 수립, 실행, 실행 결과 분석 및 판단 등 전 과정에 활용됩니다. 복잡한 개념이나 구조를 본격적으로 이해하기 전에, Nova(https://hyperlab-nova.streamlit.app/)를 먼저 테스트해 보시면 이해도를 더욱 높일 수 있을 것입니다.
Nova의 AI agent가 수행할 수 있는 태스크들
Nova는 이런 태스크들을 수행할 수 있습니다.
- KRAS에 대해 FDA 승인을 받은 약물이 있어?
- Sotorasib은 FDA 승인을 받은 약물이야?
- MARK4와 상호작용하는 단백질들은 뭐야?
- 분자의 독성을 줄이기 위해 어떤 전략들을 사용할 수 있어?
- Plerixafor의 임상시험 현황을 알려줘.
- KRAS G12D dimerization에 관한 논문들을 찾아줘.
- Vemurafenib에 관한 문헌 중 SAR 분석을 포함하는 것만 찾아줘.
Plerixafor의 임상시험 현황을 알려줘와 같은 실제 신약 개발 질문에 답하는 과정을 토대로 AI agent가 어떻게 동작하는지 이해해 보겠습니다.
1단계: 사용자 지시문 분석을 통한 계획 수립 및 실행
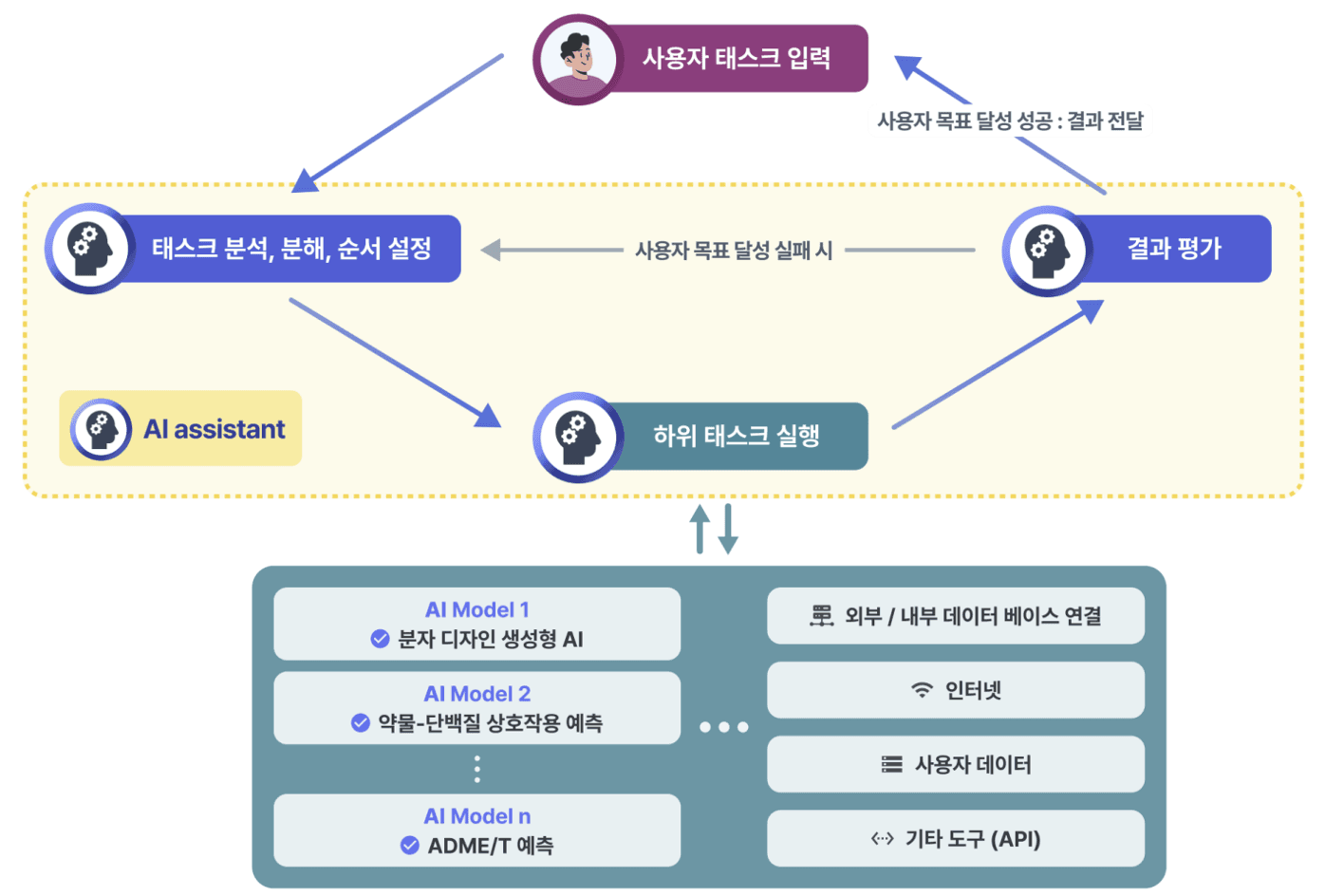
이 질문이 AI 에이전트에게 주어지면, 에이전트는 이를 바탕으로 다음에 수행할 액션을 결정합니다. 사람으로 치면 구글 검색을 해야 할지, 동료에게 물어봐야 할지, 논문을 읽어야 할지를 판단하는 것과 비슷하죠. 이를 위해 AI 에이전트에게는 사용할 수 있는 도구들의 목록과 각 도구의 사용법, 그리고 결과의 형태 등이 텍스트 형태로 제공됩니다. 이 모든 정보가 텍스트로 주어지기 때문에, AI 에이전트는 LLM을 활용해 이를 이해하고 적절한 행동을 선택할 수 있는 것입니다.
예를 들어, AI 에이전트는 임상시험 정보를 검색할 수 있는 도구와 논문 및 요약문을 받아볼 수 있는 도구를 가지고 있으며, 각 도구의 실행 방법과 결과 형태에 대한 정보도 함께 제공합니다. 에이전트는 사용자 질문에 따라 어떤 도구를 사용할지 판단하고, 선택한 도구를 적절히 실행해 원하는 정보를 얻습니다.
두 가지 도구 모두 적합하지 않다면, AI 에이전트는 스스로 답변을 생성하거나 답할 수 없다는 응답을 선택할 수도 있습니다. 모를 경우, 답변할 수 없다고 응답할 수도 있습니다. 예를 들어, Nova의 경우 위 질문에 대해 먼저 임상시험 정보 검색 도구를 실행해 결과를 받아옵니다. 이때 필요한 검색 키워드도 에이전트가 질문의 내용을 바탕으로 스스로 판단해 입력합니다.
2단계: 실행결과 분석 및 다음 계획 수립
다음 단계에서 AI 에이전트는 실행 결과를 해석합니다. 임상시험 정보 검색 도구를 통해 결과를 받아왔다면, 이 방대한 정보 중에서 사용자 지시문에 부합하는 내용을 선별해야 합니다. 검색 결과에는 사용자에게 불필요한 정보도 포함되어 있어, 적절한 내용을 추려내는 과정이 필수적입니다.
그리고 AI 에이전트는 뽑아낸 결과만으로 사용자 질문에 대한 답변을 생성하기에 충분한지를 판단합니다. Nova의 경우, 추가적인 정보가 필요하다고 판단되면 논문 검색 기능을 사용해야겠다고 결정하고 논문 검색 도구를 실행합니다. 이때도 마찬가지로 논문 검색에 사용할 키워드를 스스로 생성하며, 앞선 과정과 동일하게 논문 검색 결과를 받아 필요한 정보가 포함되어 있는지를 평가합니다.
3단계: 목표 달성 판단 및 답변 생성
임상시험 및 논문 검색 결과를 바탕으로, AI 에이전트는 사용자 질문에 대한 답변이 가능한지를 판단합니다. Nova의 경우, 두 개의 도구 실행 결과를 통해 지시문 수행에 필요한 정보를 모두 확보했다고 판단했습니다. 마지막으로, 수집한 정보들을 사용자에게 제공하기 적합한 형태로 가공한 뒤, 최종 답변을 생성하여 사용자에게 전달합니다.

이러한 AI 에이전트의 능력은 앞으로 무궁무진하게 확장될 수 있습니다. 사용자 맞춤형 데이터 분석, 코드 작성 및 실행, 문서 요약, 데이터베이스 검색 등 다양한 도구와 연동하여 더욱 복잡한 작업을 수행할 수 있게 됩니다. 특히, 신뢰할 수 있는 지식 소스를 상호 참조하여 답변을 생성하는 RAG(Retrieval-Augmented Generation)와 같은 기술과 결합될 경우, 보다 신뢰할 수 있는 결과를 제공할 수 있습니다.
AI agent의 미래와 한계
물론 AI 에이전트에는 분명한 한계점도 존재합니다. 우선, 여전히 'hallucination'이라 불리는 현상이 발생해 거짓된 정보나 존재하지 않는 문헌을 제공하는 경우가 있습니다. 잘못된 논문을 인용하거나, 오류가 포함된 코드를 작성하기도 하며, 복잡한 추론이 필요한 태스크에서는 여전히 기대에 미치지 못하는 성능을 보이기도 합니다. 그러나 주목할 점은 이러한 기술적 발전이 불과 1~2년 사이에 이루어졌다는 사실입니다. LLM의 급속한 발전과 함께 AI 에이전트의 기술 역시 매우 빠르게 진화하고 있습니다.
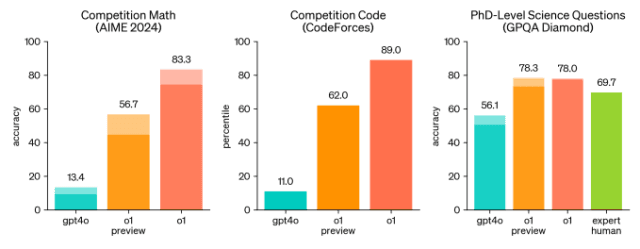
최근 공개된 OpenAI-o1은 우수한 고등학생을 대상으로 하는 AIME 수학 경시대회 문제에서 83.3%의 정답률을 기록했으며, 이는 기존 최신 모델인 GPT-4o의 13.4% 정답률을 크게 상회하는 수치입니다. 또 다른 평가에서는 박사 수준의 과학 문제에 대해 78%의 정확도로 답변했으며, 이는 GPT-4o의 56.1%뿐 아니라 인간 전문가의 평균 정확도인 69.7%까지 뛰어넘는 성과입니다. AI 에이전트들의 이러한 눈부신 발전 속도가 신약 개발 연구에 어떤 혁신을 가져올지, 상상만으로도 매우 흥미롭습니다.