딥시크 AI, LLM의 판도를 뒤흔들다!


딥시크 AI에 관하여
최근 AI 업계에서 큰 주목을 받고 있는 딥시크 AI에 대해 살펴보고, 혁신적인 비용 절감과 높은 성능을 동시에 달성한 방법을 분석해보겠습니다.
중국 AI 스타트업 딥시크 AI는 2025년 1월 20일 DeepSeek-R1 모델을 공개했습니다. 이 모델은 OpenAI의 o1 모델과 비교해도 뛰어난 성능을 자랑하며, 특히 수학, 코드, 논리적 추론에서 강점을 보입니다. 또한 MIT 라이선스로 공개되어 누구나 자유롭게 사용, 수정 및 배포할 수 있어 더욱 주목받고 있습니다. DeepSeek-R1은 그 이전 버전인 DeepSeek-V3에 기반을 두고 있습니다. 그러니 먼저 DeepSeek-V3에 대해 알아보죠.
딥시크 AI의 DeepSeek-V3
거대 언어 모델(LLM)은 수많은 파라미터를 필요로 하기 때문에 연산 비용이 막대합니다. 딥시크 AI의 DeepSeek-V3는 두 가지 핵심 기술을 활용해 이러한 연산량을 획기적으로 줄였습니다.
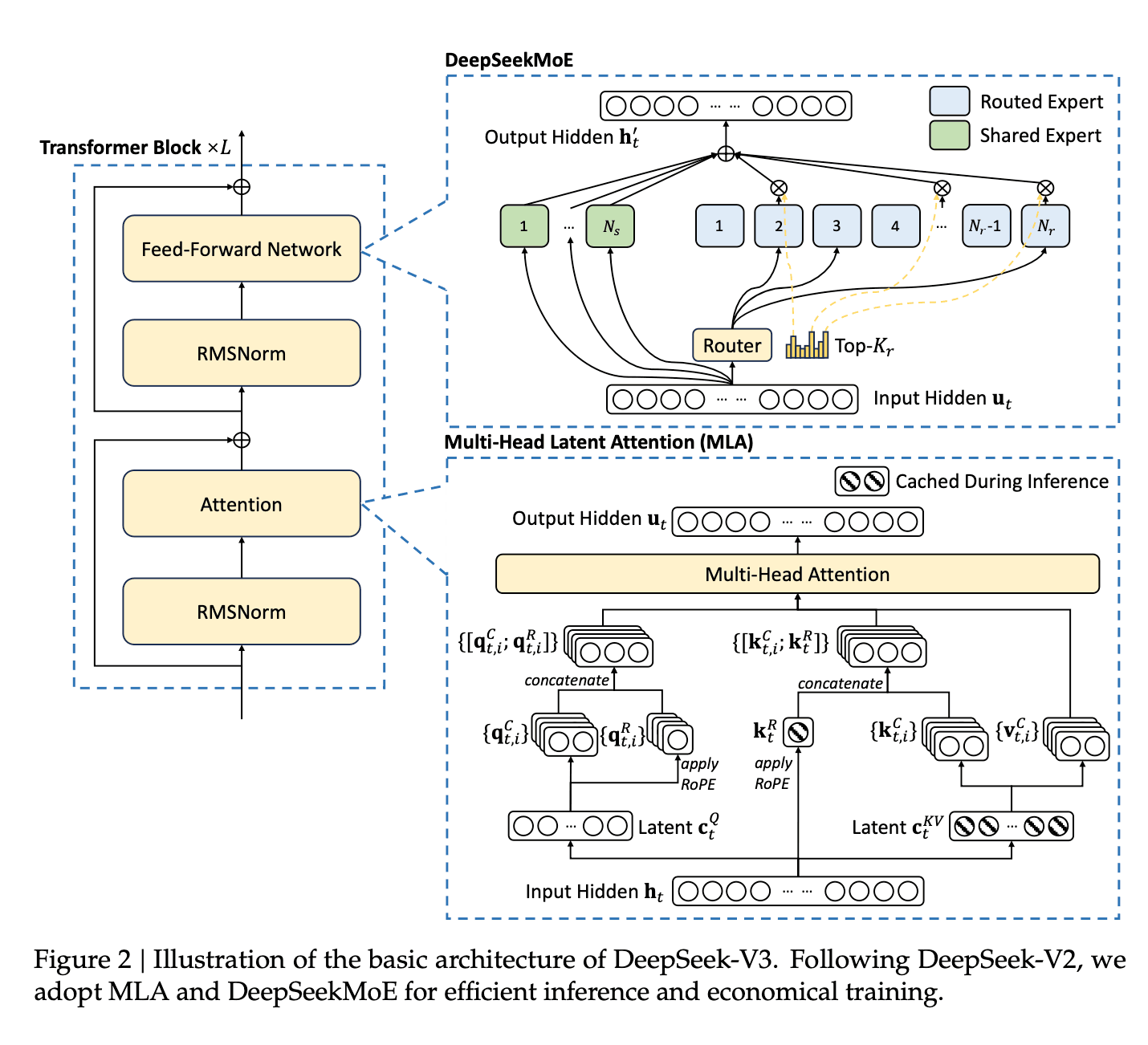
1. MoE (Mixture of Experts) 기술
먼저 MoE입니다. 기존 딥러닝의 앙상블 개념과 유사한 방식으로, 딥시크 AI는 이를 개선하여 더욱 효율적인 모델을 구축했습니다. MoE는 여러 개의 Expert(전문가) 신경망과 이를 조율하는 Router(라우터)로 구성됩니다. 라우터는 하나의 레이어로서 입력 토큰을 어떤 Expert가 이용하는 것이 좋을지 판단합니다. 각각의 Expert는 서로 다른 입력 토큰에 대해 서로 다른 예측 분포를 가집니다. 꼭 하나만 사용될 필요는 없으며, 그림처럼 한 번에 여러 개(K개)의 Expert가 동시에 쓰일 수도 있습니다.
이렇게 되면 전체 모델의 파라미터 수는 크지만, 매 토큰 계산 시 일부 Expert만 활성화되기 때문에 연산 속도에서 큰 이점을 얻을 수 있습니다. 여기까지의 MoE 방법은 기존에도 이미 활용되던 방식입니다.
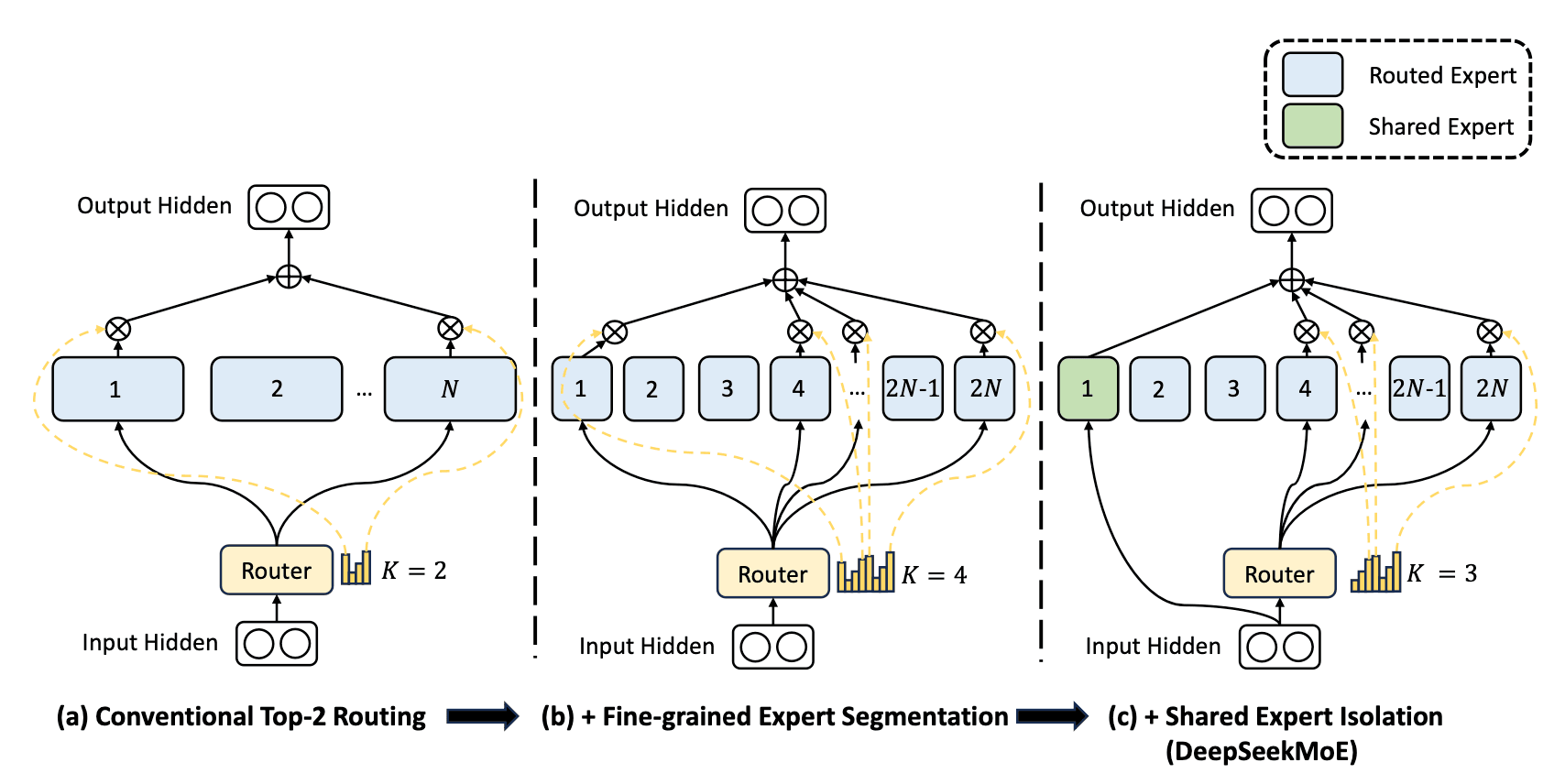
딥시크 AI 연구진들은 여기에 새로운 방식을 제안하였습니다. 위 그림의 (c)처럼 Shared Expert를 추가하는 것입니다. 이 Shared Expert는 각 Expert가 가지고 있는 전문 지식이 아닌 일반 지식을 갖도록 학습되어 있으며, 그 이름처럼 어떤 토큰이 와도 항상 활성화되는 Expert입니다.
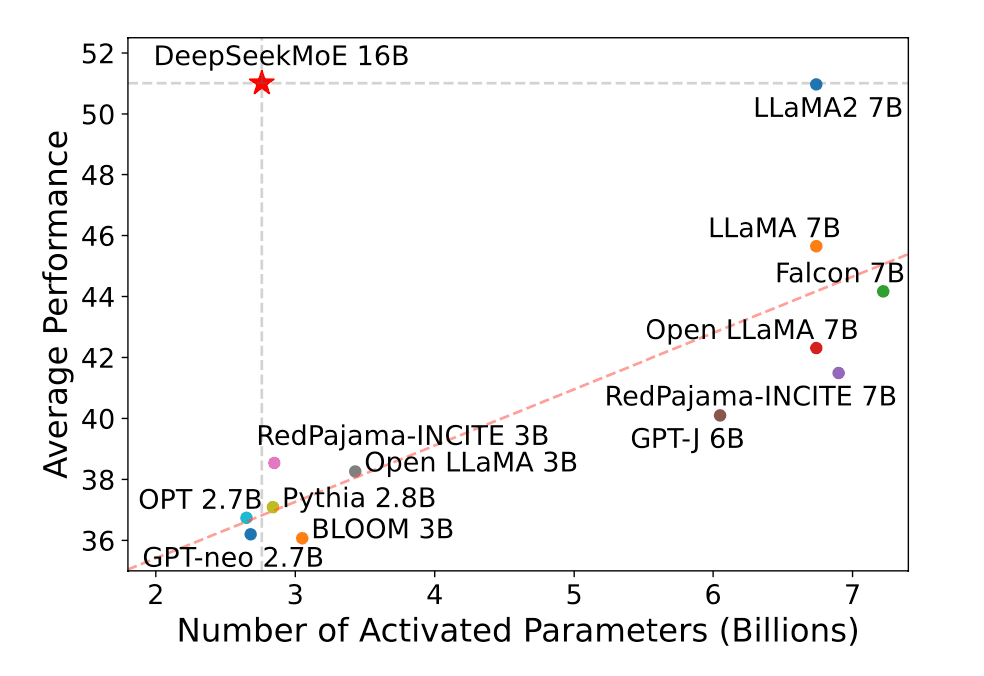
이 방식 덕분에 DeepSeek-V3는 총 671B의 파라미터를 갖고 있음에도 불구하고, 실질적으로 매 토큰을 예측할 때 활성화되는 파라미터는 37B에 불과합니다. 활성화되는 파라미터가 적다는 것은 컴퓨팅 연산 측면에서 매우 유리하다는 뜻이며, 이는 딥시크 AI가 기존 LLM 대비 훨씬 낮은 비용으로 고성능을 유지할 수 있음을 의미합니다. 아래의 그림을 보면 성능 대비 활성화 파라미터의 개수가 비교도 안 될 만큼 적다는 것을 알 수 있습니다.
하지만 오해하면 안 되는 중요한 점이 있습니다. 해당 모델을 구동하기 위해서는 모든 파라미터를 한꺼번에 메모리에 올려야 합니다. 매 토큰마다 사용되는 파라미터 수는 37B가 맞지만, 토큰마다 선택되는 Expert가 다르기 때문에 결국 전체 파라미터를 메모리에 올려둬야 하는 것입니다.
따라서 여전히 상당한 고성능의 그래픽 카드는 필요합니다. 이해를 돕기 위한 아래의 그림은 MoE를 LLM 분야에 성공적으로 도입한 모델인 Mixtral 연구에서 발췌한 것입니다. 각 토큰에 대해 강조된 색깔이 다른 것을 보면, 학습한 지문(소스 코드)에 대해 매우 다양한 전문가가 골고루 사용되었다는 것을 알 수 있습니다.

2. MLA (Multi-Head Latent Attention) 기법
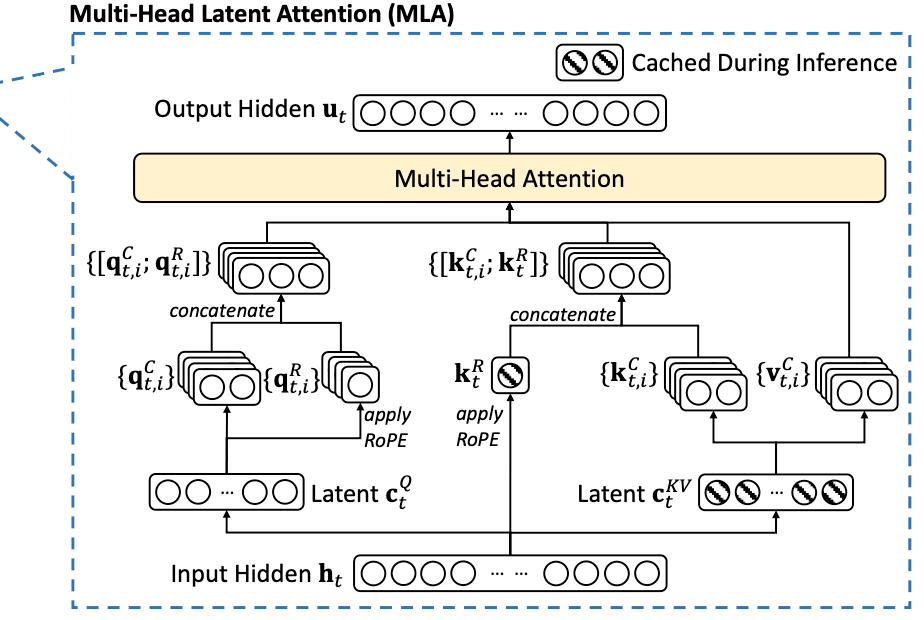
MLA는 기존의 Multi-Head Attention 구조를 개선한 형태로, 딥시크 AI가 연산량을 줄이고 메모리 효율성을 높일 수 있도록 만든 기술입니다. MLA의 핵심 아이디어는 Key와 Value 벡터를 더 작은 차원으로 압축하는 방식입니다. \(t\)번째 토큰의 attention 입력 \(\mathbf{h}_t\)에 학습 가능한 파라미터인 Projection 행렬을 곱해서 압축된 저차원의 KV 벡터 \(\mathbf{c}_t^{KV}\)를 얻는 것이 핵심 아이디어입니다. 이렇게 MLA를 통해 성능은 유지하면서, 메모리의 사용량은 줄이는 게 가능했습니다
이러한 방식으로 딥시크 AI는 성능 저하 없이 메모리 사용량을 현저히 줄일 수 있었습니다. 기존의 Multi-Head Attention과 달리, 빗금친 부분의 잠재 벡터만 캐시에 저장하여 Multi-Head Attention을 수행함으로써 메모리 효율을 높일 수 있는 것입니다.
딥시크 AI의 DeepSeek-R1
이제부터 소개할 모델은 DeepSeek-R1입니다. DeepSeek-R1은 ChatGPT의 O1, O3 모델과 같은 Reasoning 모델입니다. 따라서 사용자의 메시지에 바로 대답하는 것이 아니라, 모델이 스스로 생각한 사고 과정을 바탕으로 추론하여 답을 내놓습니다. DeepSeek-R1은 DeepSeek-V3을 기반으로 한 모델이며, GRPO라는 강화학습 기법이 적용된 모델입니다.
GRPO(Group Relative Policy Optimization)는 2024년 DeepSeek에서 새롭게 소개된 강화학습 기법입니다. 하지만 일반적인 강화학습과는 달리, GRPO는 Critic 없이 학습을 수행하는 것이 특징입니다.
따라서 Critic 모델이 가치 함수를 학습해서 정책을 평가하는 대신에, 이전 정책 \(\pi_{\theta_{\text{old}}}\)으로부터 얻은 그룹 내 출력값 \(\{ o_1, o_2, \dots, o_G \}\)들을 현재 정책 \(\pi_{\theta}\)의 출력들 \(\{ o_1, o_2, \dots, o_G \}\)과 서로 비교하여 상대적인 랭크를 계산하여 정책을 업데이트합니다.
GRPO의 목적함수는 다음과 같습니다.
\[ \begin{equation*}
\mathcal{J}_{GRPO}(\theta) = \mathbb{E}\left[q \sim P(Q), \{o_i\}_{i=1}^{G} \sim \pi_{\theta_{\text{old}}}(O|q)\right] \\\frac{1}{G} \sum_{i=1}^{G} \left( \min \left( \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)} A_i, \text{clip} \left( \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)}, 1-\epsilon, 1+\epsilon \right) A_i \right) \right) \\- \beta \mathbb{D}_{KL} \left( \pi_{\theta} \| \pi_{\text{ref}} \right)
\end{equation*} \]
여기서 \(q\)는 입력 질문, \(o_i\)는 \(i\)번째 그룹에 속하는 출력입니다. 그리고 \(\epsilon\)과 \(\beta\)는 하이퍼파라미터입니다.
따라서 \(\frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)} \) 는 주어진 출력 \(o_i\)이 있을 때, 현재의 정책 \(\pi_\theta\)과 직전의 정책 \(\pi_{\theta_{\text{old}}}\)의 비율입니다. 즉, 현재의 정책이 직전의 정책보다 더 높은 확률 분포를 가진다면 이 값은 1보다 클 것입니다. clip은 clipping 연산을 한다는 의미인데, \(\frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)} \)값이 \(1-\epsilon\),\(1+\epsilon\)사이에서 지나치게 큰 범위로 벗어나지 않도록 합니다.
\(\mathbb{D}_{KL}\) 항은 현재의 정책\(\pi_\theta\)과 기준이 되는 정책\(\pi_\text{ref}\) 사이의 확률 분포 차이를 계산하는 KL Divergence 연산입니다. 이 항의 역할은 기준이 되는 정책(V3 모델의 정책)과 현재 정책이 다를수록 목적 함수에 페널티를 가하는 항으로 이해하면 됩니다. \(A_i\)는 Advantage 항으로, 다음과 같이 계산됩니다. 이 수식은 그룹 내 보상 값들을 이용하여 개별 보상을 정규화하는 역할을 합니다.
\[ A_i = \frac{r_i - \text{mean}(\{r_1, r_2, \cdots, r_G\})}{\text{std}(\{r_1, r_2, \cdots, r_G\})} \]
딥시크 AI 연구진은 위와 같은 방식으로 지도 학습이 전혀 개입되지 않은 모델을 DeepSeek-R1-Zero라 명명했습니다. DeepSeek-R1-Zero 모델의 성능은 기대보다 좋았지만, 결과물의 낮은 가독성과 Language mixing 문제(한 대답 안에 두 언어가 섞이는 문제)가 종종 발생했습니다.
딥시크 AI 연구진은 이러한 DeepSeek-R1-Zero 모델의 한계가 콜드 스타트 때문이라고 판단하여, 수천 개의 질 좋은 Chain of Thought 데이터를 이용해 사전학습을 시킨 뒤, 이를 토대로 강화학습을 시작해 DeepSeek-R1 모델을 얻었습니다. 그 결과, DeepSeek-R1은 위의 두 문제를 해결했을 뿐만 아니라 더 나은 Reasoning 성능을 보였습니다.
딥시크 AI의 증류 모델
딥시크 AI 연구진은 DeepSeek-R1의 답변 수십만 개를 활용해 기존 Qwen 및 Llama 모델을 파인튜닝하여 여섯 가지 증류 모델을 제작했습니다. 놀라운 점은 OpenAI o1-mini 모델과 유사한 성능을 보이면서도, 토큰당 비용이 50배 이상 저렴하다는 것입니다. 이는 LLM 서비스의 상업적 활용 가능성을 크게 높이는 요소입니다.
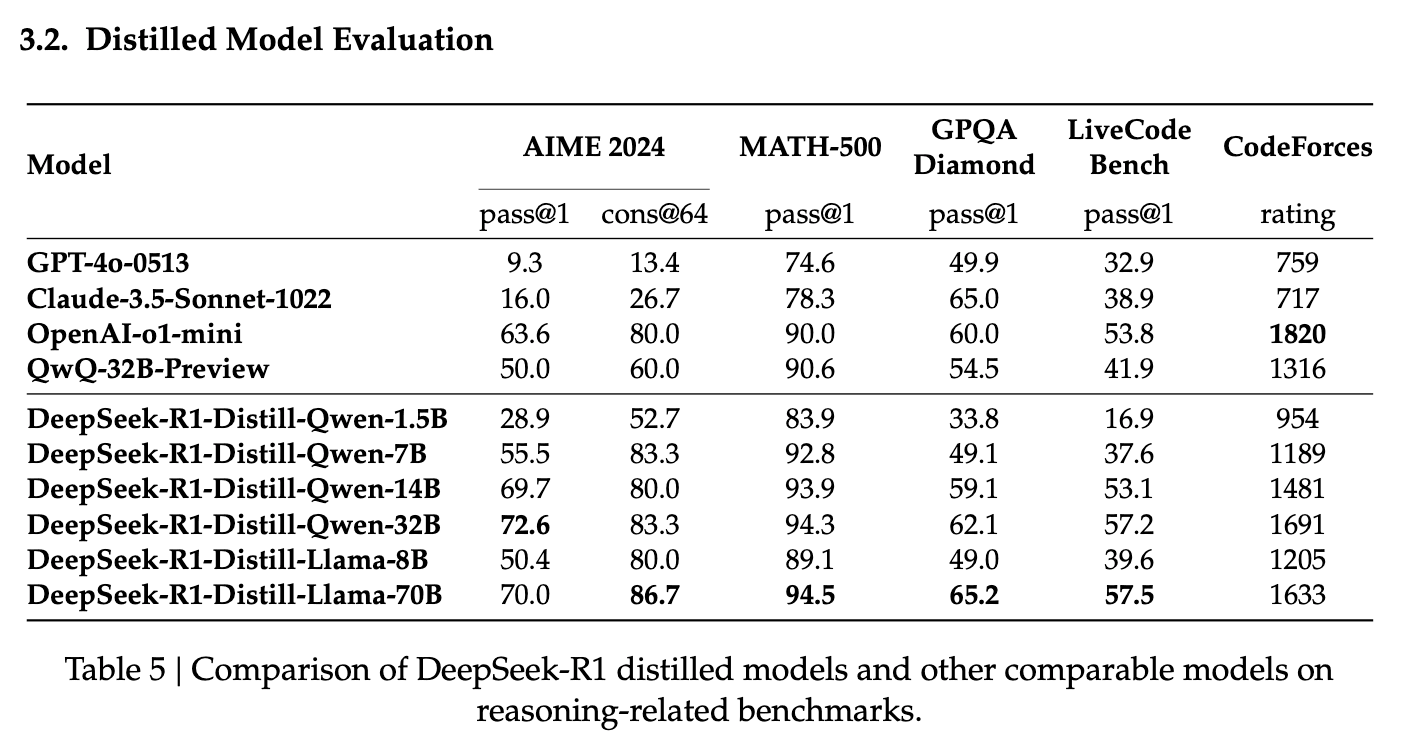
현재 이 여섯 가지 증류 모델은 Ollama 플랫폼에 업로드되어 있어, 로컬 환경에서 직접 체험할 수 있습니다.
맺음말: 딥시크 AI의 미래
이번 DeepSeek가 제시한 기술적 혁신은 계산 비용 절감과 학습 효율성 향상을 통해 AI 연구의 새로운 지평을 열었다고 할 수 있습니다. 강화학습을 활용한 모델 최적화, MoE 아키텍처 도입, 그리고 오픈소스를 통한 연구 협업 증진과 같은 접근법은 LLM의 성능을 향상시키는 동시에, 보다 효율적이고 경제적인 AI 개발을 가능하게 만들고 있습니다. 앞으로의 연구는 단순히 모델의 크기를 확장하는 것이 아니라, 더욱 정교한 학습 전략과 최적화 기법을 통해 더욱 강력하고 신뢰할 수 있는 AI 시스템을 구축하는 방향으로 나아갈 것으로 기대됩니다.
AI 신약개발 플랫폼 하이퍼랩
- 무료체험 https://abit.ly/ew6yeh
- 도입문의 https://abit.ly/yyytsg