DeepSeek AI : A Breakthrough in AI Efficiency


DeepSeek AI: A Breakthrough in AI Efficiency
DeepSeek AI has recently emerged as a major player in the AI industry, offering cutting-edge models with high performance at a significantly lower cost. In this article, we will explore how DeepSeek AI has achieved such efficiency and examine the core innovations that set it apart.
On January 20, 2025, the Chinese AI startup DeepSeek AI introduced DeepSeek-R1, a model that competes with OpenAI's o1 model. Notably, DeepSeek-R1 excels in mathematical reasoning, coding, and logical inference. Moreover, it is released under the MIT license, allowing unrestricted use, modification, and distribution, which has significantly contributed to its growing popularity.
To fully understand DeepSeek-R1, let’s first look at its predecessor, DeepSeek-V3.
DeepSeek AI’s DeepSeek-V3
Large language models (LLMs) require vast computational resources, leading to high operational costs. DeepSeek AI’s DeepSeek-V3 leverages two key techniques to dramatically reduce computation requirements without sacrificing performance.
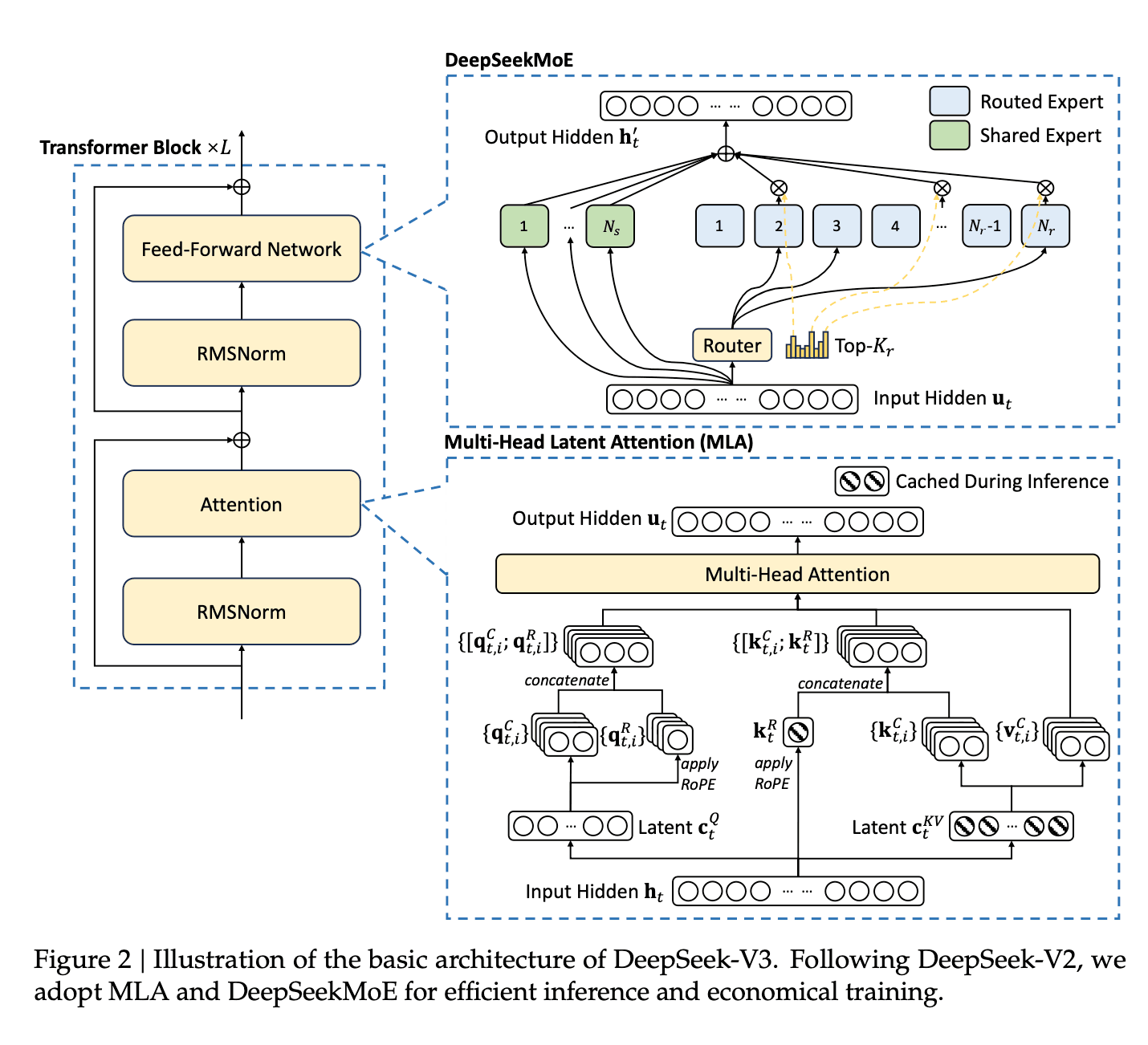
1. MoE (Mixture of Experts) Technology
Mixture of Experts (MoE) is a deep learning technique similar to ensemble learning, and DeepSeek AI has optimized this approach for efficiency. MoE consists of multiple expert neural networks managed by a router, which determines which experts should process a given token.
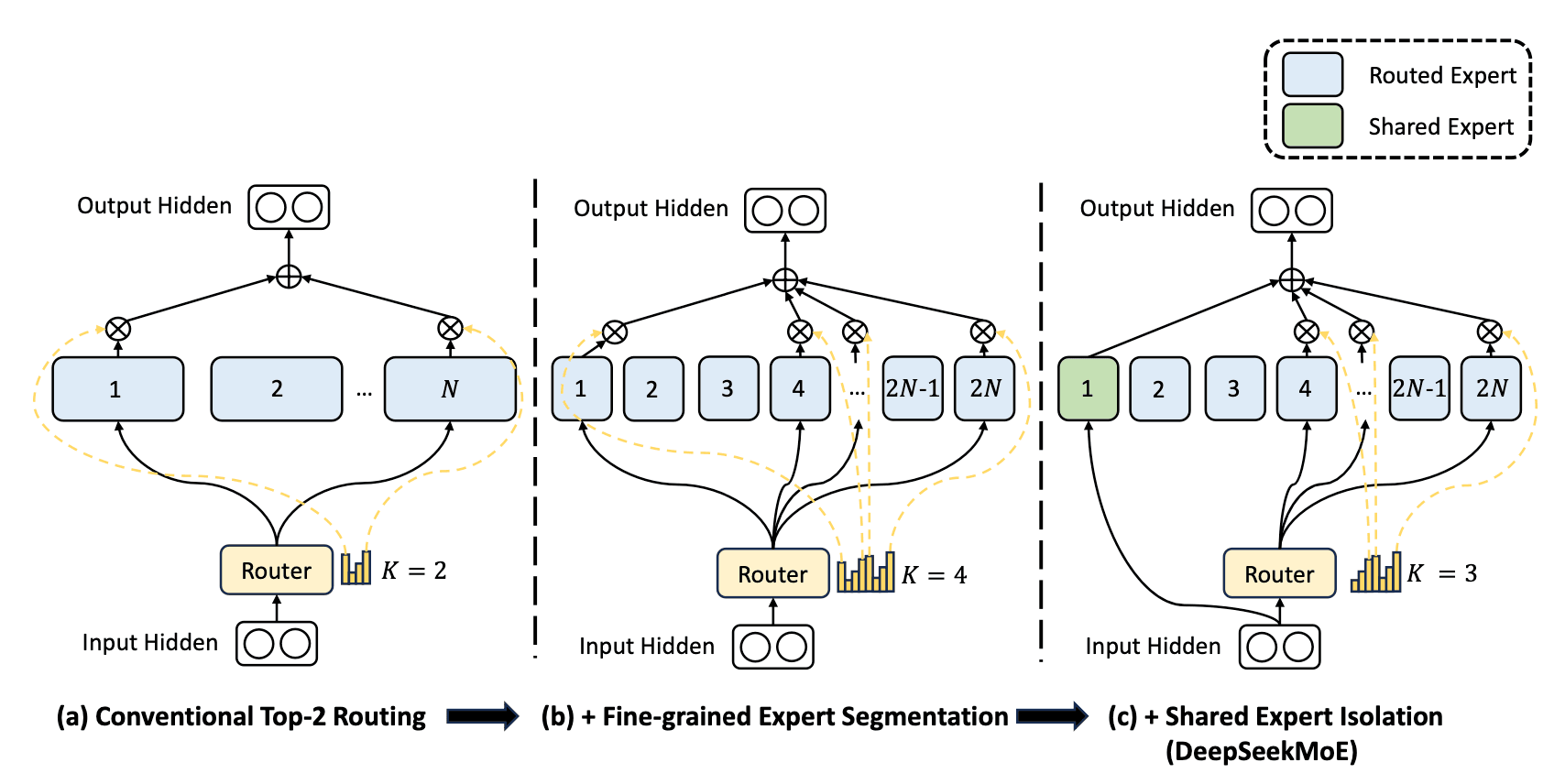
DeepSeek AI’s key innovation is the introduction of a Shared Expert, which is always active and trained with general knowledge. This design allows DeepSeek-V3 to maintain a total of 671B parameters while activating only 37B per token, significantly reducing computation costs.
However, all parameters still need to be loaded into memory, meaning high-performance GPUs remain necessary. To further optimize efficiency, DeepSeek AI integrates additional techniques.

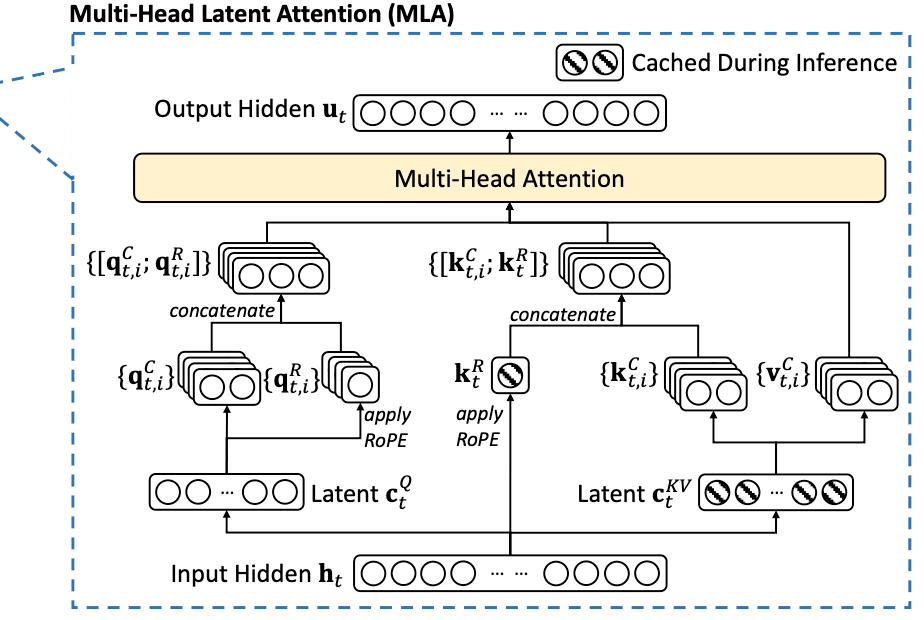
2. MLA (Multi-Head Latent Attention) Mechanism
MLA is an improved version of the traditional Multi-Head Attention structure, designed by DeepSeek AI to reduce computational costs and enhance memory efficiency. The core idea of MLA is to compress the Key and Value vectors into smaller dimensions. The key concept is multiplying the attention input \(\mathbf{h}_t\) of the \(\t\) -th token by a learnable projection matrix to obtain the compressed lower-dimensional KV vectors \(\mathbf{c}_t^{KV}\). With MLA, performance is maintained while memory usage is reduced.
This method has allowed DeepSeek AI to significantly reduce memory usage without sacrificing performance. Unlike the traditional Multi-Head Attention, only the latent vectors in the striped sections are stored in cache, optimizing memory efficiency.
DeepSeek AI’s DeepSeek-R1
Now, let’s introduce DeepSeek-R1. DeepSeek-R1 is a reasoning model similar to ChatGPT’s o1 and o3 models. Thus, instead of immediately answering a user’s message, the model infers and provides an answer based on its own thought process. DeepSeek-R1 is based on DeepSeek-V3 and incorporates a reinforcement learning technique called GRPO.
GRPO (Group Relative Policy Optimization) is a new reinforcement learning method introduced by DeepSeek in 2024. However, unlike traditional reinforcement learning, GRPO performs learning without a Critic model.
Instead of having a Critic model learn the value function and evaluate policies, GRPO compares the output from the previous policy \(\pi_{\theta_{\text{old}}}\) with the output from the current policy \(\pi_{\theta}\) calculates the relative rank, and uses that to update the policy.
The objective function for GRPO is as follows:
\[ \begin{equation*}
\mathcal{J}_{GRPO}(\theta) = \mathbb{E}\left[q \sim P(Q), \{o_i\}_{i=1}^{G} \sim \pi_{\theta_{\text{old}}}(O|q)\right] \\\frac{1}{G} \sum_{i=1}^{G} \left( \min \left( \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)} A_i, \text{clip} \left( \frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)}, 1-\epsilon, 1+\epsilon \right) A_i \right) \right) \\- \beta \mathbb{D}_{KL} \left( \pi_{\theta} \| \pi_{\text{ref}} \right)
\end{equation*} \]
Here, \(q\) represents the input question, and \(o_i\)is the output corresponding to the \(i\) group. The hyperparameters are \(\epsilon\) and \(\beta\).
Thus, \(\frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)} \) represents the ratio between the current policy \(\pi_\theta\) and the previous policy \(\pi_{\theta_{\text{old}}}\) when given the output \(o_i\).
In other words, if the current policy has a higher probability distribution than the previous one, this value will be greater than 1. The term "clip" refers to the clipping operation, which ensures that \(\frac{\pi_{\theta}(o_i|q)}{\pi_{\theta_{\text{old}}}(o_i|q)} \) does not deviate excessively outside the range of \(1-\epsilon\) , \(1+\epsilon\) .
THe \(\mathbb{D}_{KL}\) term computes the KL divergence, which measures the difference in probability distributions between the current policy \(\pi_\theta\) and the reference policy \(\pi_\text{ref}\). This term penalizes the objective function more when the current policy differs more from the reference policy (which is the policy of the V3 model).
The \(A_i \) term, called the Advantage, is calculated as follows. This formula normalizes individual rewards using the group’s reward values:
\[ A_i = \frac{r_i - \text{mean}(\{r_1, r_2, \cdots, r_G\})}{\text{std}(\{r_1, r_2, \cdots, r_G\})} \]
The research team named this model, which was entirely unsupervised, DeepSeek-R1-Zero.
The performance of the DeepSeek-R1-Zero model exceeded expectations but still faced issues such as low readability and language mixing problems (where two languages were mixed in a single answer).
The team determined that these limitations of the DeepSeek-R1-Zero model were due to a cold start. To overcome this, they pre-trained the model using thousands of high-quality Chain of Thought data and then began reinforcement learning. This led to the development of the DeepSeek-R1 model, which not only solved the previous issues but also demonstrated improved reasoning performance.
DeepSeek AI’s Distilled Models
DeepSeek AI leveraged hundreds of thousands of DeepSeek-R1 responses to fine-tune existing LLMs, such as Qwen and Llama, producing six highly optimized distilled models.
What makes these models remarkable is their performance comparable to OpenAI’s o1-mini while being 50 times more cost-effective per token. This cost efficiency makes large-scale AI deployment significantly more accessible.
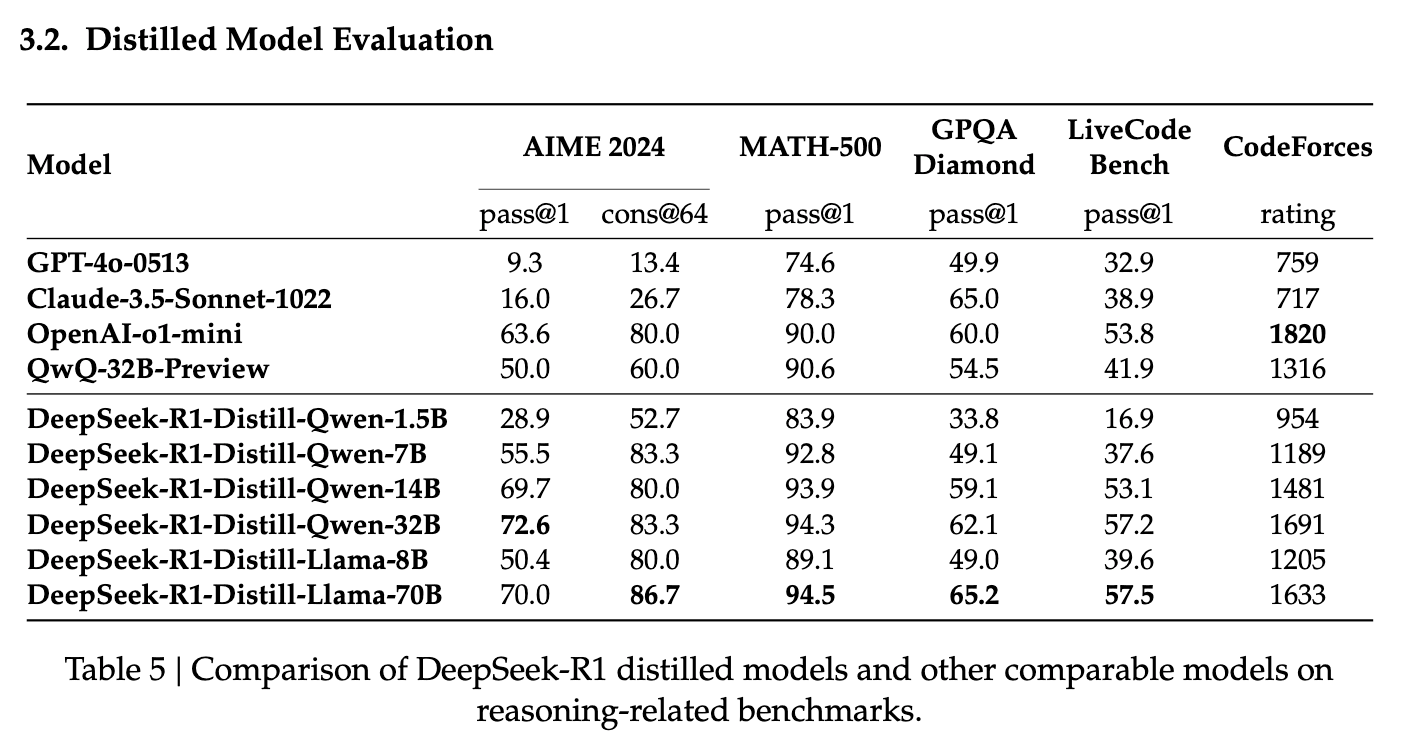
Currently, all six distilled models are available on Ollama, allowing developers to experiment with them in local environments.
Conclusion: The Future of DeepSeek AI
DeepSeek AI’s technological breakthroughs are shaping the future of AI research and deployment. By focusing on computational efficiency, optimized training strategies, and open-source collaboration, DeepSeek AI is paving the way for more scalable, reliable, and cost-effective LLMs.
Looking ahead, DeepSeek AI will likely continue refining its training methodologies and optimization techniques, prioritizing not just model size but overall performance and efficiency.
AI drug discovery platform, Hyper Lab
Start your free trial https://abit.ly/irbdbe
Schedule a meeting https://abit.ly/6tr1uz