트랜스포머 기반의 분자 학습 도구, Uni-Mol


⚠️ 이번 글은 LLM(Large Language Model)의 학습에 사용되는 Transformer에 대한 기초적인 선행지식이 필요합니다.
오늘은 Uni-Mol이 Transformer 모델을 활용해 분자의 3차원 위치 정보를 어떻게 예측하는지 간략히 살펴보겠습니다. 특히 그중에서 히츠에서 중요한 태스크 중 하나인 단백질-리간드 결합 포즈 예측에 초점을 맞춰 자세히 알아보겠습니다.
ICLR 2023에 실린 Uni-Mol이란?
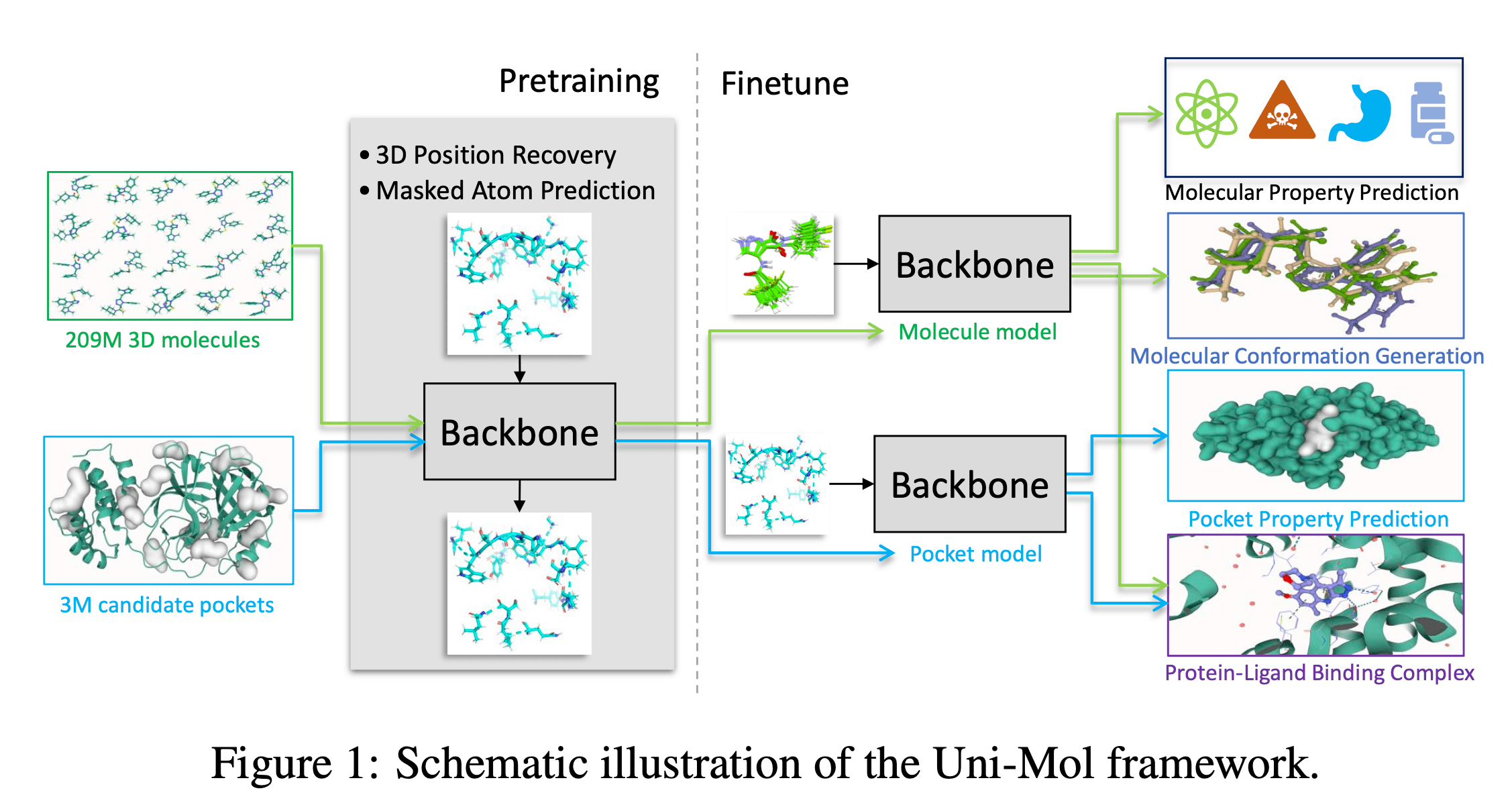
Uni-Mol은 2023년 ICLR에서 발표된 논문, “UNI-MOL: A UNIVERSAL 3D MOLECULAR REPRESENTATION LEARNING FRAMEWORK”에서 처음 소개된 분자 학습 프레임워크입니다. 이름에서 알 수 있듯, 다양한 태스크를 수행할 수 있는 범용 프레임워크로 개발되었으며, 단백질과 분자의 3차원 좌푯값을 예측하는 데 특화되어 있습니다. 논문에 따르면, Uni-Mol은 ADMET과 같은 분자의 물성 예측, 3차원 컨포머 생성, 그리고 단백질-리간드 결합 포즈 예측 등 다양한 분야에 활용될 수 있다고 합니다. Uni-Mol의 가장 큰 특징은 Transformer 기반의 분자 표현 학습(Molecular Representation Learning) 기술을 적용했다는 점입니다.
트랜스포머 기반의 Backbone 구조
Uni-Mol은 Transformer 모델을 기반으로 하고 있습니다. Transformer는 주로 LLM(Large Language Model) 학습에 널리 사용됩니다. Uni-Mol에서 다양한 딥러닝 모델 중 Transformer를 선택한 이유는 멀리 떨어진 원자들 사이의 상호작용 정보를 효과적으로 학습할 수 있기 때문입니다. 다만 Transformer를 그대로 사용할 수는 없는데, 이는 Transformer가 자연어 처리에 특화된 모델이기 때문입니다. 따라서 Uni-Mol에서는 다음과 같은 요소들을 추가로 고려해야 합니다.
첫 번째로, 연속적인 값을 다뤄야 한다는 점입니다. 우리가 예측하려는 3차원 좌표의 위치 값은 연속적인 반면, Transformer에서 사용하는 토큰의 위치 값은 이산적입니다. 따라서 Positional Encoding 과정에서 기존 Transformer처럼 이산적인 값이 아니라 연속적인 값을 처리해야 합니다. 이를 위해 가우시안 커널을 활용해 float 타입을 임베딩하는 방식을 적용했습니다.
두 번째로, Positional Encoding 과정은 회전(Rotation)과 이동(Translation)에 대해 불변(Invariant)해야 한다는 점입니다. 단백질이나 리간드가 임의의 공간에서 회전하거나 이동하더라도 결국 같은 단백질과 리간드이기 때문입니다. 이러한 제약을 극복하기 위해 Uni-Mol은 모든 원자 쌍에 대해 거리(pair-distance)를 계산합니다. 원자 간 거리를 활용하면 이후 과정에서 회전과 이동에 대해 불변한 연산을 수행할 수 있기 때문입니다.
Pair representation 계산
이제 Pair representation을 계산할 차례입니다. 특정 원자와 그 원자와 쌍을 이루는 다른 원자 하나를 Pair라고 하며, 그 쌍에 대한 표현 정보를 Pair representation이라고 합니다. Pair representation은 다음과 같은 방식으로 계산됩니다.
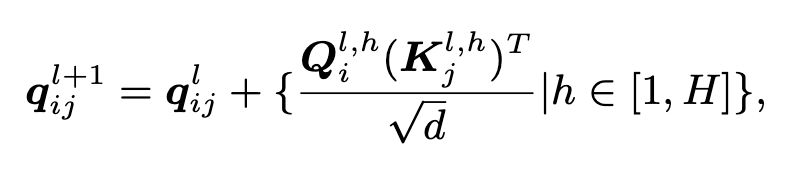
Uni-Mol은 더 나은 성능을 위해 Multi-Head Attention을 사용합니다. Query, Key, Value를 각각 H개로 나누어 병렬로 연산을 진행합니다.
Pair representation을 계산하는 이유는 바로 아래에서 등장하는 Context Vector를 구하기 위함입니다. 우리가 익숙한 Attention Mechanism 식에 Pair Representation 항이 추가된 것을 확인할 수 있습니다. Context Vector는 Pretraining 과정의 최종 출력값이 됩니다.

사전학습 진행하기 - Pretraining
기존 Transformer에서는 특정 토큰을 마스킹한 후, 그 토큰을 예측하는 방식으로 Encoder 학습이 진행됩니다. Uni-Mol에서는 두 가지 사전 학습(Pretraining) 모델이 필요합니다. 하나는 특정 원자가 어떤 종류의 원소인지 예측하는 모델이고, 다른 하나는 특정 원자의 3차원 좌푯값을 예측하는 모델입니다.
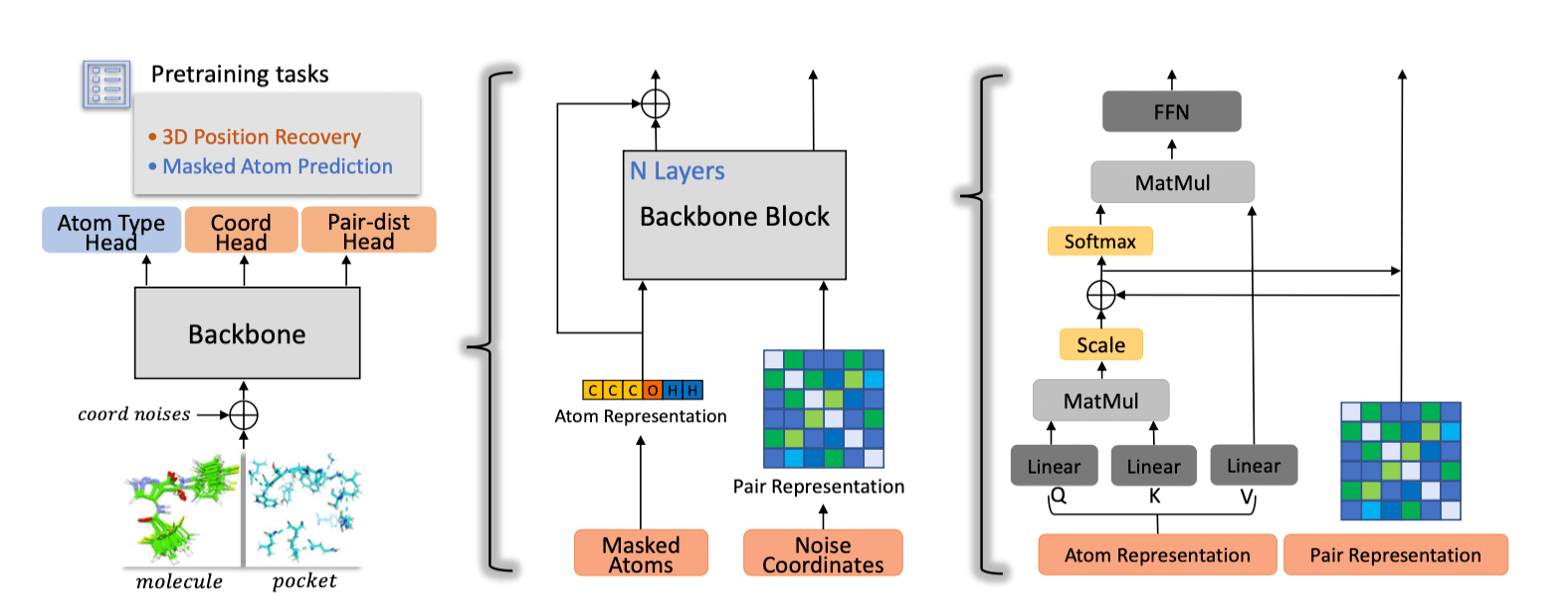
이 두 가지 모델을 학습하기 위해 Uni-Mol에서는 다음과 같은 데이터셋을 사용했습니다.
- 3차원 좌푯값을 포함하는 분자(리간드) 약 2억개
- 3차원 좌푯값을 포함하는 단백질 포켓 구조 약 320만개
첫 번째 모델, 즉 특정 원자가 어떤 종류의 원소인지를 예측하는 모델에서는 기존 Transformer처럼 마스킹 기법을 활용합니다. 데이터셋에 포함된 분자나 단백질 내 임의의 원자를 특수한 기호로 대체하며, 이 원자의 3차원 좌푯값은 해당 분자나 단백질에 포함된 전체 원자들의 무게 중심으로 설정합니다. 하지만 두 번째 모델인 3차원 좌푯값을 예측하는 모델에서는 앞서 설명한 방식을 사용할 수 없습니다. Uni-Mol이 예측하는 원자들의 3차원 좌푯값은 이산적인 값이 아닌 연속적인 값이기 때문입니다.
따라서 Uni-Mol은 기존 Transformer처럼 토큰을 마스킹하는 대신, Ground Truth 원자 위치에 최대 1Å(옹스트롬) 범위 내에서 가우시안 노이즈를 추가하는 방식을 사용해 3차원 좌푯값을 변형합니다. 이후 변화된 3차원 좌푯값이 정답 구조와 잘 맞도록 학습이 진행됩니다.
이 학습 과정을 통해 Atom Representation과 Pair Representation을 학습하는 것이 Pretraining 과정의 주요 목적입니다.
단백질-리간드 결합포즈 예측하기 - Finetuning
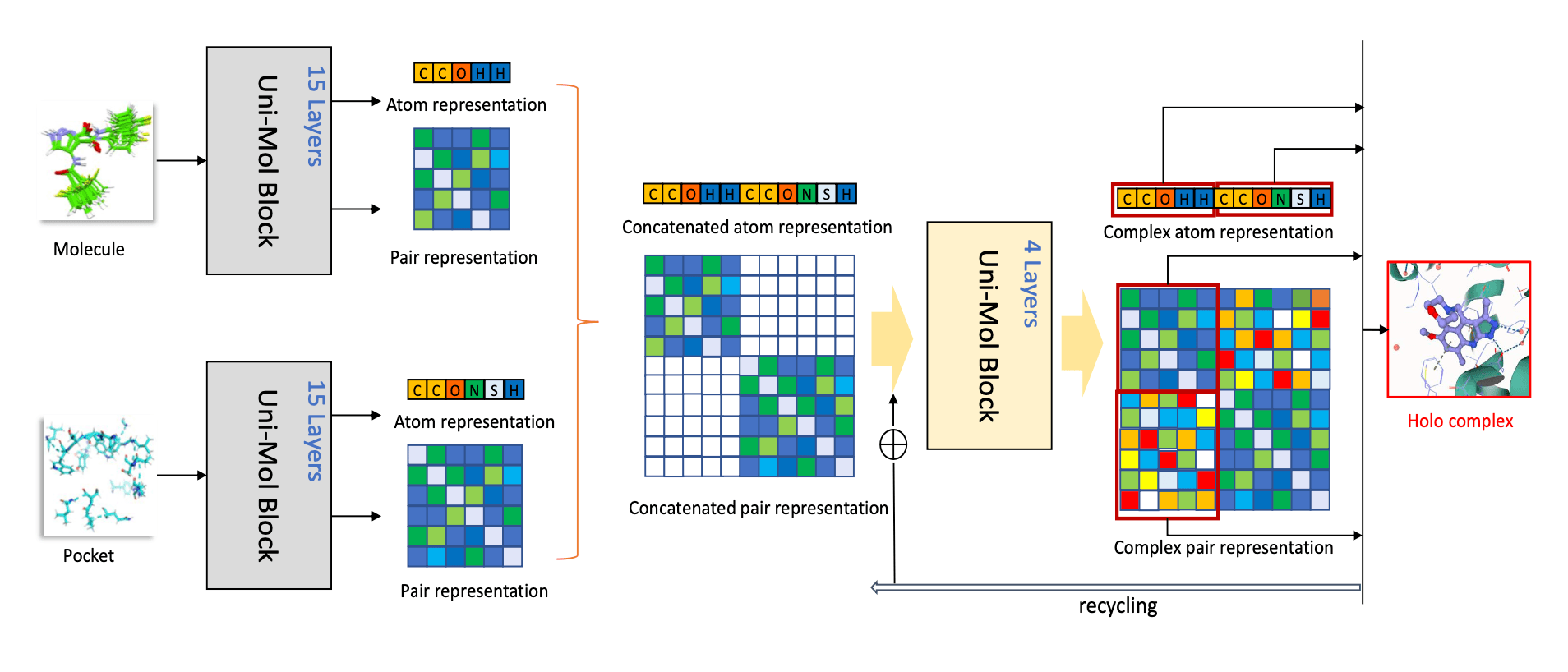
앞서 우리는 Pretraining 모델을 학습하는 방법을 알아보았습니다. 이제 마지막 단계인 결합 포즈 예측 단계로 넘어가겠습니다. 우리의 목적은 단백질-리간드 결합 포즈를 예측하는 것입니다. 예측하고자 하는 분자(리간드)와 단백질을 각각 Pretraining 모델에 입력하여 Encoding을 진행합니다. 그러면 분자와 단백질 각각에 대한 Atom Representation과 Pair Representation을 얻을 수 있겠죠?
이제부터는 Decoding 과정입니다. Decoder의 입력은 Encoder에서 얻은 모든 Representation을 연결(concatenate)한 값으로, 초기 도킹 포즈에 대한 표현 정보입니다. 초기 도킹 포즈는 조금이라도 무작위로 선정되면 Decoder의 출력이 크게 변동할 수 있기 때문에, 이를 안정적으로 얻기 위해 Pretrained 모델을 이용해 Encoding을 진행한 것입니다.
이렇게 얻은 Representation들을 연결하여 Decoder의 입력으로 사용합니다.
Decoder 내부에서는 현재의 Pair-distance matrix와 예측된 Pair-distance matrix 간의 MSE(Mean Square Error)를 Loss로 삼아 Back-propagation을 진행하며 학습이 이뤄집니다. 이 과정을 통해 단백질-리간드 결합 포즈가 최적화됩니다. Uni-Mol 연구진은 단백질-리간드 결합 포즈 예측 성능을 평가하기 위해 CASF-2016 데이터를 벤치마크로 사용했습니다.
Fine-tuning 결과, Uni-Mol의 단백질-리간드 결합 포즈 예측 정확도는 80.35%에 달한다고 합니다. CASF-2016 데이터에는 총 285개의 단백질-리간드 쌍이 포함되어 있으며, 이 80.35%라는 수치는 전체 285개 중 정답 구조와 RMSD가 2Å 이하로 측정된 결과물이 229개였다는 의미입니다. 이는 논문 출간 시점을 기준으로 최첨단(State-Of-The-Art, SOTA) 성능에 해당합니다.
마치며
최근 Transformer 기반 딥러닝 모델은 컴퓨터 비전뿐만 아니라 다양한 분야에 응용되고 있습니다. Uni-Mol 이후로도 어떤 새로운 모델이 개발될지 기대가 됩니다. 이상으로 오늘의 포스팅을 마치겠습니다. 다음에는 더욱 도움이 될 새로운 주제로 찾아뵙겠습니다.