KCC 2024 다시 보기


KCC(Korea Computer Congress) 소개

한국정보과학회에서 주최하는 한국컴퓨터종합학술대회(Korea Computer Congress, KCC)는 매년 6월에 진행되는 저명한 국내 학회로, 컴퓨터 및 정보과학 분야 전반의 연구들이 발표됩니다.
올해 KCC 2024는 ‘초거대 AI와 SW 혁신이 이끄는 미래 사회’를 주제로 개최되었으며, 네이버 클라우드, Intel, 카카오, SK하이닉스 등의 후원 아래 국내 전산학 연구를 이끄는 많은 연구실이 참여하였습니다.
히츠 AI 연구팀은 올해 처음으로 KCC 2024에 AI 연구팀이 참여하여 산학에서 발표되는 첨단 연구들을 살펴보았습니다. 고성능 컴퓨팅, 국방, 데이터베이스, 모바일 시스템, 사물인터넷, 스마트 시티, 언어공학, 인공지능 등 다양한 분야에서 800건이 넘는 논문이 발표되었습니다.
이번 글에서는 해당 논문들 중 크게 네 개의 주제를 선정하여, 주제별로 발표된 연구들을 살펴보겠습니다.
신약개발 관련 연구

이번 KCC 학회에는 빅데이터 및 AI 기반 CADD 쪽 도메인에 관련된 재미있는 연구도 여럿 있었는데요. 그 중 저희가 인상 깊게 본 연구를 3가지 정도 추려 소개해 보고자 합니다.
빅데이터와 AI를 활용해 새로운 리간드를 최적화하다
첫 번째로, 빅데이터 분석 기법 및 AI를 활용한 새로운 리간드 최적화 과정 방법론을 제시한 연구를 소개하겠습니다. 본 연구에서는 기존 방식의 약물 최적화, 즉 hit-to-lead가 주로 의약화학자의 경험과 노하우에 의존하여 효율성과 정확성에 근본적인 한계가 있음을 지적합니다.
이에 연구진은 리간드 분자를 약리학적 특성을 지니는 원자단인 Pharmacophore에 해당하는 Core와 Branch로 분리하고, 새로운 Branch를 Core에 조합하여 기존 라이브러리에 없는 새로운 아날로그를 생성하고 최적화하는 방법을 개발하였습니다.
이때 Core의 Branch site 수를 최대 2개로 제한하고, 분자 구조의 유사성을 나타내는 Tanimoto Similarity를 기반으로 Branch 클러스터링을 수행하여 전체 탐색 공간을 효과적으로 줄였습니다. 이를 통해 전체 프로세스의 효율성을 높일 수 있었습니다.
이후 약물 활성 평가(QED), 합성 가능성(RA Score), 합성 용이성(SA Score)을 통해 최적화된 아날로그를 선별하고, AI 모델을 이용해 단백질과의 결합력(DTA)을 평가합니다. 마지막으로 선정된 아날로그들에 대해 AutoDock Vina를 통한 도킹 시뮬레이션을 진행하여 최적화 신뢰성을 검증하였습니다.
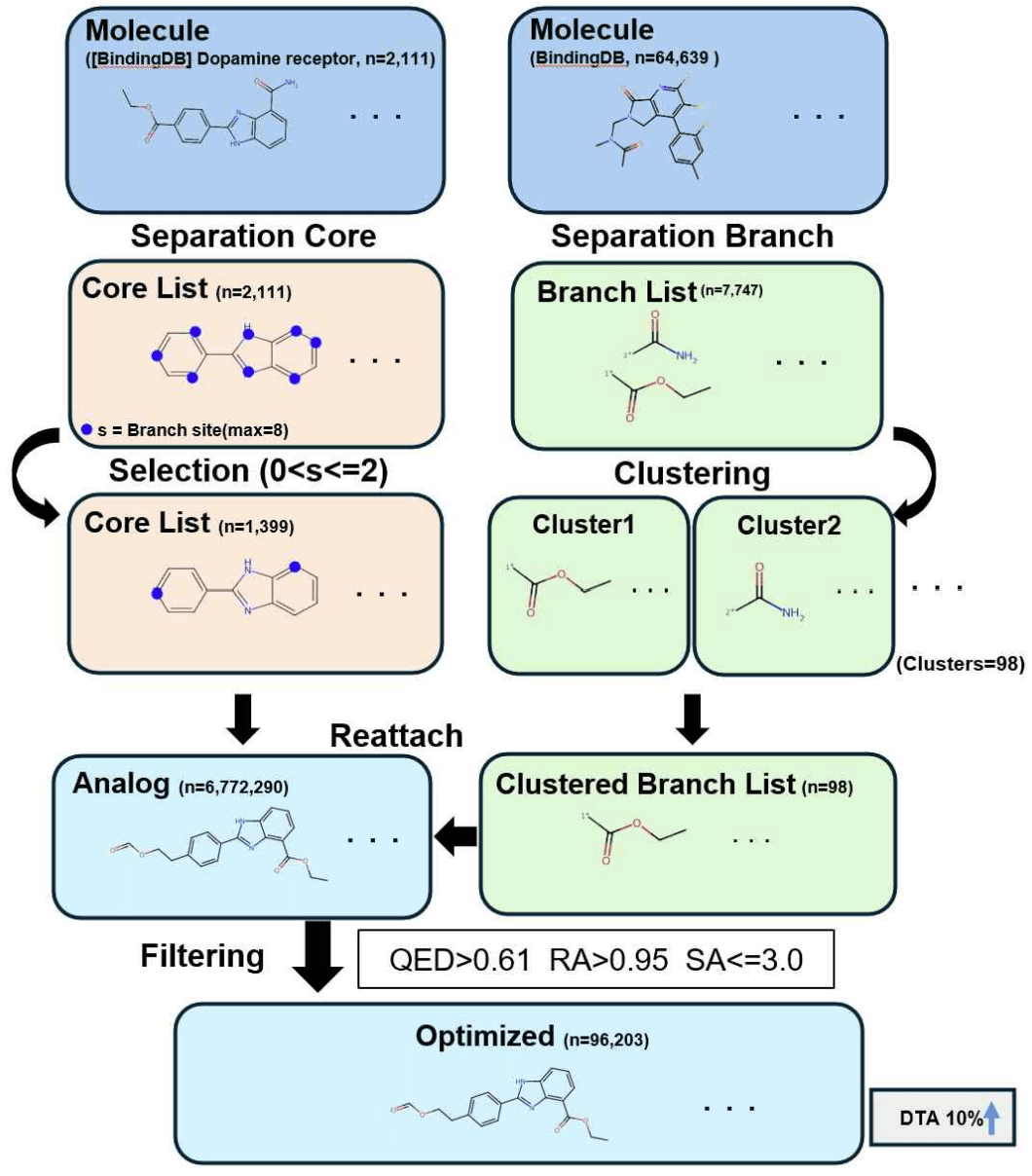
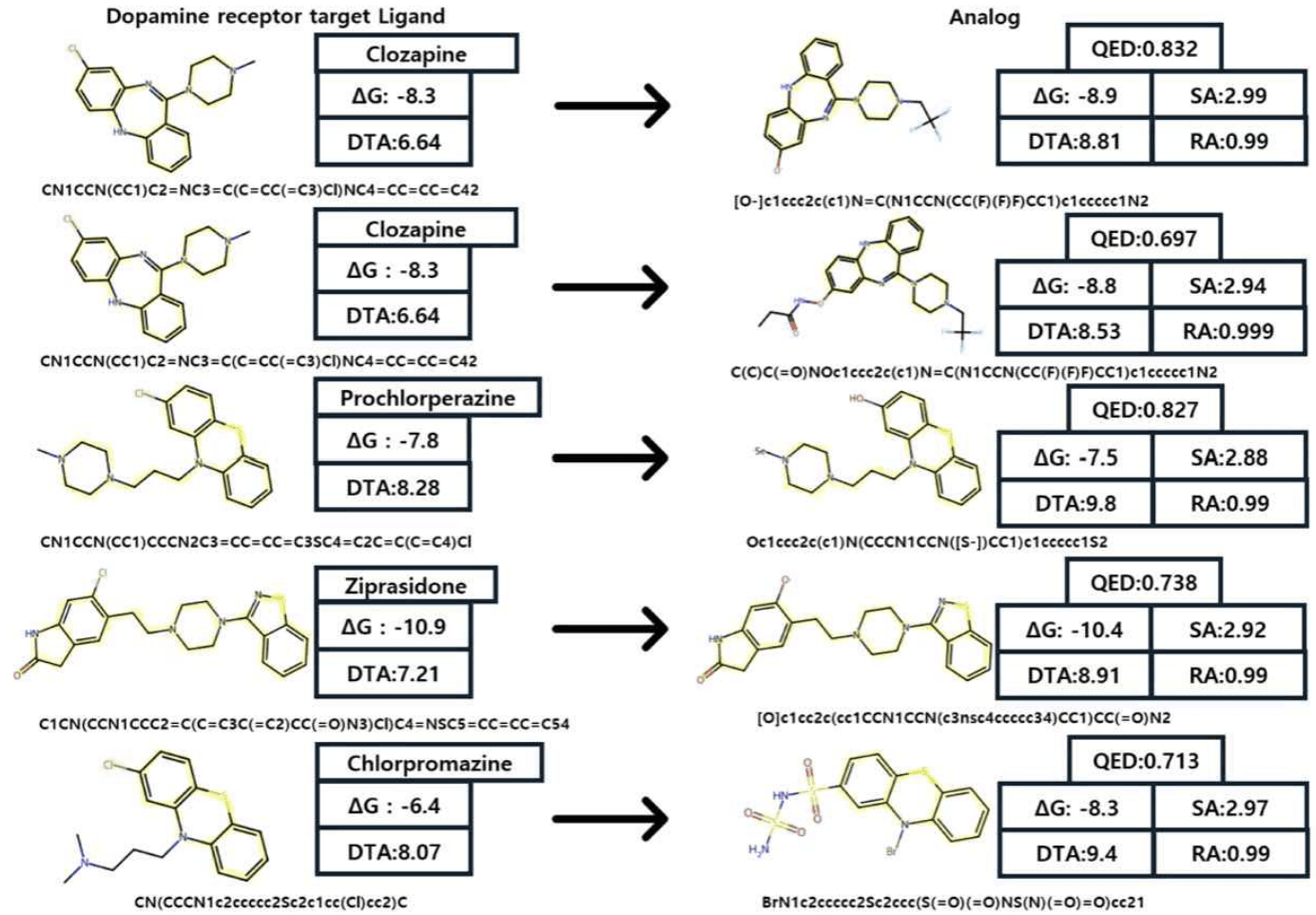
해당 연구에서는 도파민 수용체를 표적 단백질로 하여 실험을 진행한 결과, 최적화 조건을 만족하는 아날로그 96,203개를 도출하였습니다. 새로운 아날로그 분자들은 기존 데이터베이스에 없는 신규 분자로, 도파민 수용체와의 도킹 시뮬레이션 결과 기존 약물 분자와 유사하거나 더 우수한 결합력을 보여, 제시한 방법론이 효과적임을 입증하였습니다.
정리하자면, 본 연구는 축적된 빅데이터와 오픈 소스로 공개된 AI 모델을 훌륭히 활용함과 동시에, 의약화학적 배경 지식을 가미하여 기존 방식보다 효율적이고 더 데이터에 입각한 hit-to-lead 과정을 제시했다고 할 수 있습니다.
분자 그래프 신경망의 Soft Label 효과 확인 및 Regression Smoothing 기법 제안
앞서 소개한 연구에서 선별한 아날로그의 표적 단백질에 대한 결합력(DTA)을 평가하기 위해 AI 모델을 활용하였다는 점을 기억하실 겁니다. 이처럼 DTA나 분자 특성 예측과 같은, 실험적으로 측정한 라벨을 예측하는 지도 학습 모델들은 라벨 생성에 영향을 미친 실험 환경 요인 등으로 인해 라벨 품질이 저하되어 AI 모델의 학습 성능이 떨어질 위험이 있습니다.
이번에 소개할 연구는 분자의 구조를 그래프 형태로 활용하는 그래프 신경망 모델(Graph Neural Network, GNN)에서 이러한 문제를 해결하기 위해 라벨 스무딩 기법과 소프트 라벨을 제안합니다.
라벨 스무딩이란, 이산적인 라벨을 가지는 분류(classification) 태스크에서 1 또는 0으로 이루어진 하드 라벨을 특정 값만큼 조정한 소프트 라벨로 모델을 학습시켜, 모델이 정답에 대해 덜 확신하도록 유도하는 딥러닝 기법입니다. 하지만 일부 분자 특성 예측 태스크나 DTA 예측 문제처럼 연속적인 라벨 값을 맞추는 회귀(regression) 태스크는 소프트 라벨을 직접 만들기 어렵습니다.
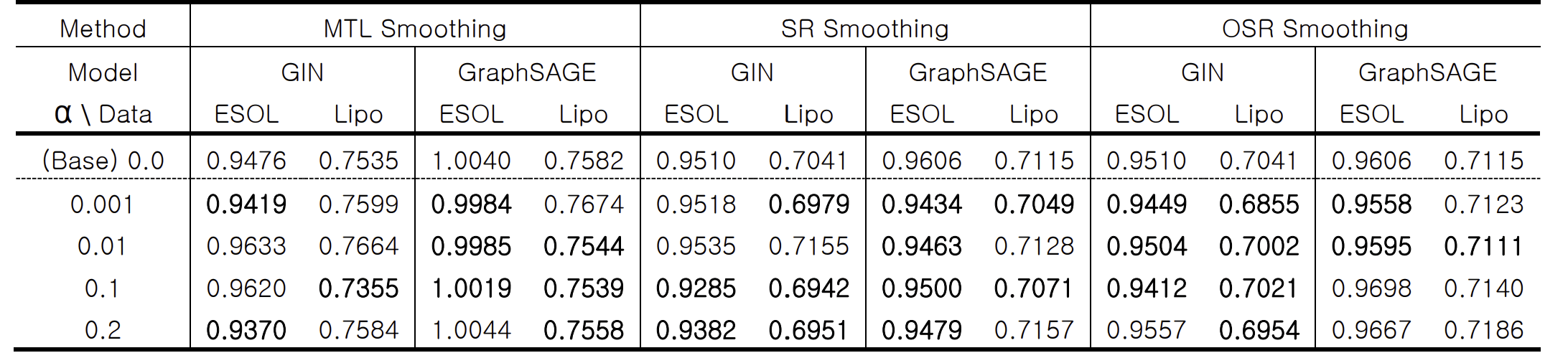
따라서 연구진은 회귀 태스크에 대해 다음과 같은 세 가지 라벨 스무딩 방법을 고안하고 실험을 진행하였습니다.
첫째, 다중 작업 학습(Multi-task Learning)을 통해 분류 문제를 추가하고 소프트 라벨을 적용하는 MTL Smoothing, 둘째, 학습 데이터의 정답 값에 대한 통계량(표준편차)을 활용하여 정답 값의 범위 내에서 랜덤하게 추출한 값을 라벨로 사용하는 SR Smoothing, 셋째, SR Smoothing을 확장한 방법으로, 예측 값이 정답 범위 내에 있을 경우 업데이트를 진행하지 않는 OSR Smoothing입니다.
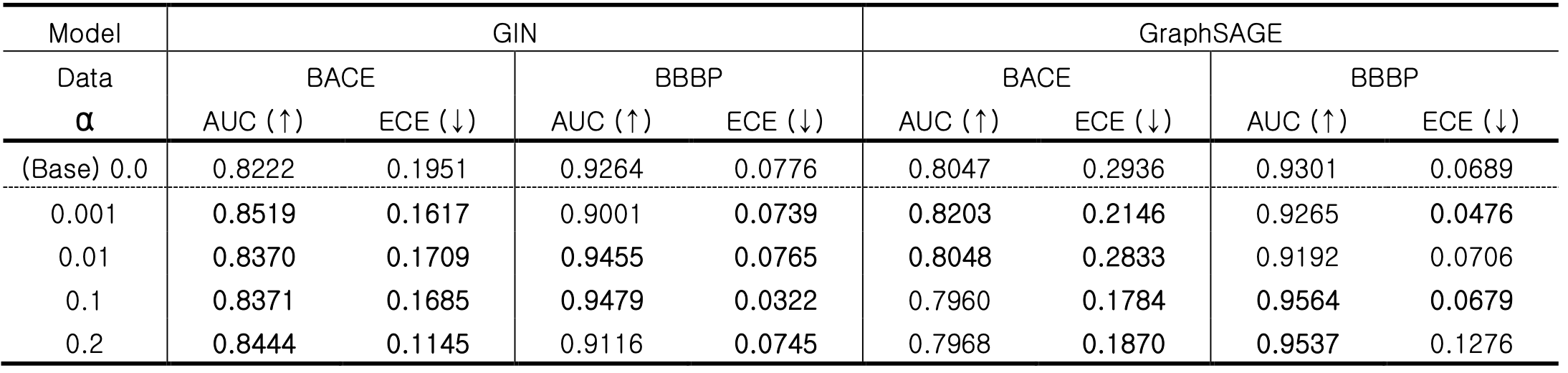
아래 표에 정리된 실험 결과를 보면, 분류 태스크에서 소프트 라벨을 적용할 경우 적용하지 않은 케이스 대비 분류 성능(AUC)과 캘리브레이션 능력(ECE)이 향상됩니다.
또한 회귀 태스크에서는 제안한 3가지 스무딩 방법 모두, 스무딩을 적용하지 않은 베이스라인 대비 예측 성능(RMSE)이 감소하여 예측력이 좋아졌습니다. 특히 SR Smoothing과 OSR Smoothing은 MTL Smoothing보다 유의미한 성능 향상을 보였습니다.
즉, 라벨 스무딩을 통해 GNN 모델이 데이터 라벨에 내재된 불확실성을 학습하여, 실전 데이터에서 더욱 강건한 예측력을 가지게 된 것입니다. 이는 특히 실험적 불확실성이 내재된 의약화학 데이터를 학습 및 예측하는 AI 모델의 성능 향상에 더욱 효과적일 것으로 기대됩니다.
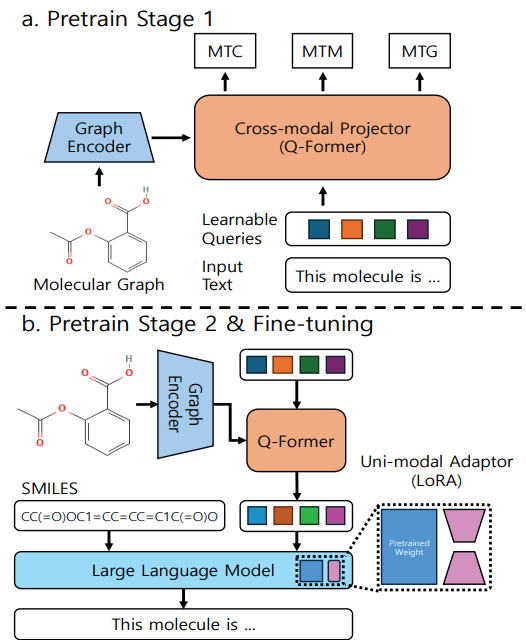
멀티모달 그래프 – LLM에서 SMILES 표현을 통해 분자의 이해 향상
ChatGPT의 등장으로 촉발된 거대 언어 모델(LLM)의 발전은 이제 자연어에만 국한되지 않고 이미지, 음성 등 여러 형태의 데이터를 통합하는 멀티모달(multi-modal)로 확장되고 있습니다. 따라서 도메인에 대한 전문적인 지식이나 데이터를 LLM에 통합하여 특정 태스크에 특화된 LLM을 개발하고자 하는 연구가 활발히 이루어지고 있는데요.
특히 화학 분야에서는 그래프로 나타낸 분자 구조 정보와 LLM에서 나온 자연어 표현이 연관되도록 한 MolCA가 대표적입니다. MolCA는 분자의 그래프 구조 정보를 압축하는 GNN encoder와 Q-Former라고 불리는 신경망을 학습시켜, 압축된 분자 구조 정보를 자연어 정보로 사영(projection)시킵니다. 그리고 Q-Former를 통해 각 분자 구조마다 적절한 자연어 입력값을 형성하여, 분자의 SMILES와 함께 LLM 모델에 넣어 적절한 출력값이 나오도록 LLM 모델을 포함한 전체 모델을 미세 조정합니다.
이번에 소개할 연구는 MolCA에서 사용된 GNN encoder가 오직 분자의 구조 정보로만 학습된 단일 모달 모델임을 주목합니다. 이를 MoMu라는 분자의 그래프 구조와 텍스트를 함께 학습한 멀티모달 GNN encoder로 대체하여 성능을 높이는 방법을 제시합니다.
또한 MolCA처럼 학습 전 과정에서 GNN encoder를 업데이트하는 방식에서, 마지막 미세 조정 단계에서만 업데이트하거나 아예 업데이트하지 않는 방식으로 변경하여 GNN encoder가 사전에 분자 구조와 텍스트로부터 학습한 지식을 잘 보존할 수 있도록 하였습니다.
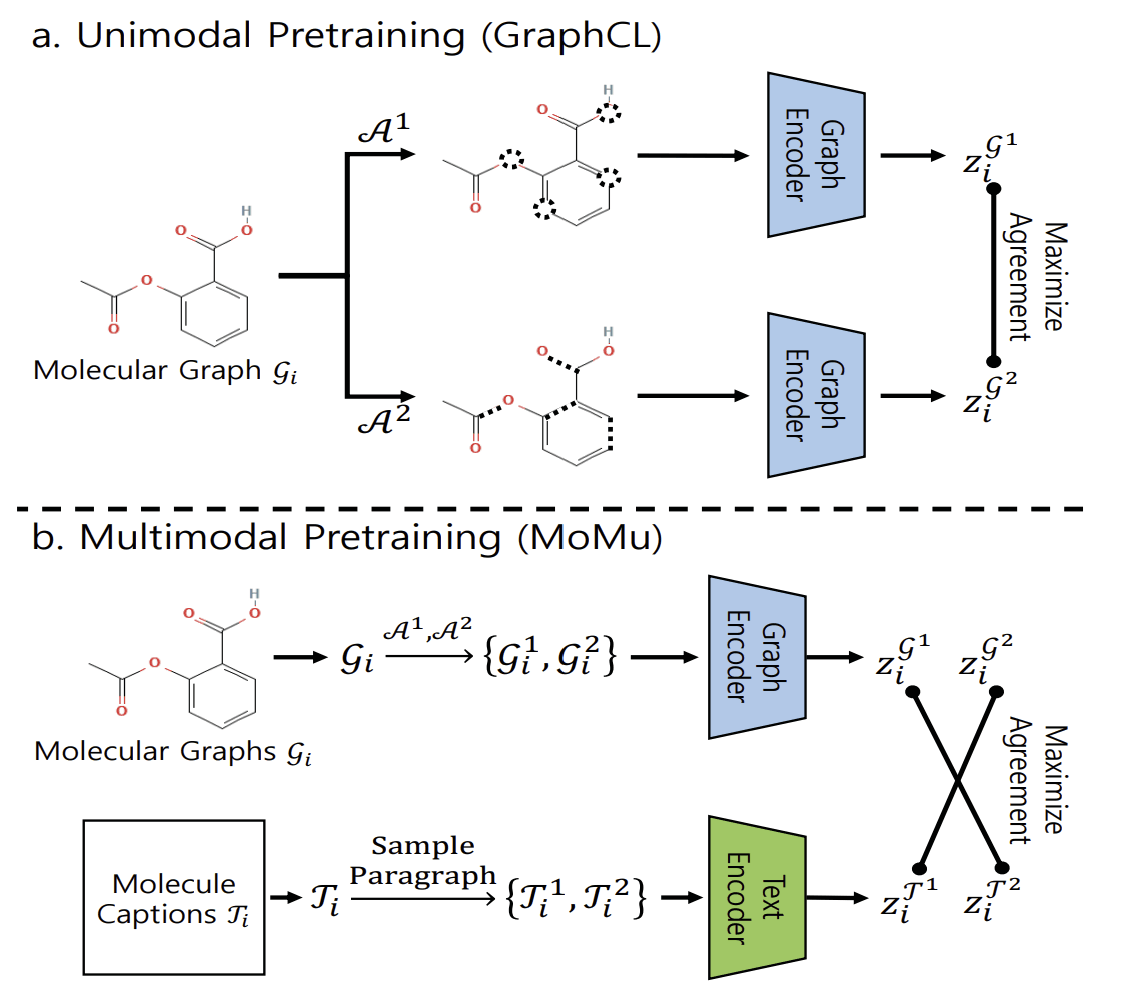
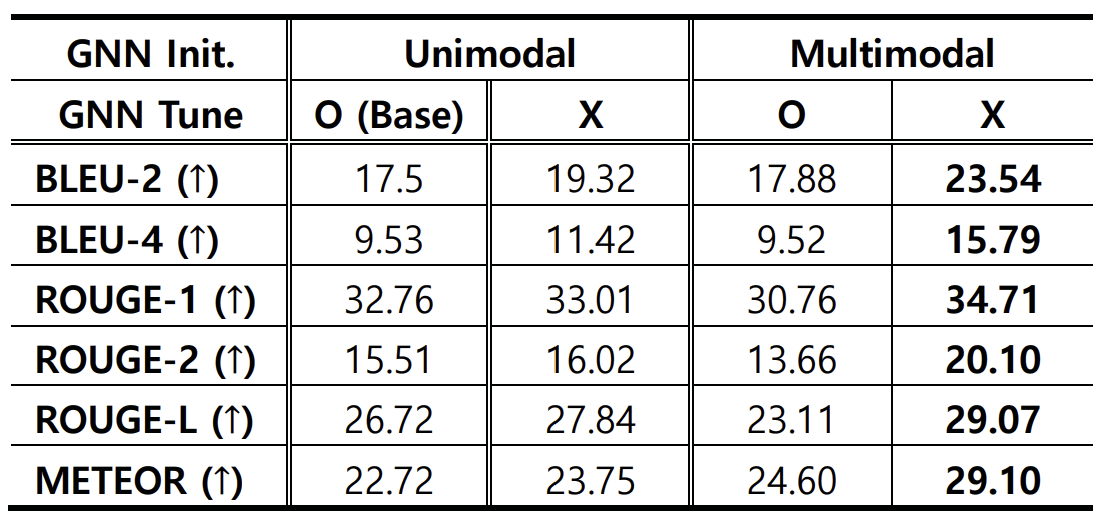
연구진들은 PubChem 데이터베이스로부터 추출한 분자들의 설명 생성(molecule captioning) 태스크를 통해 실험을 진행하였고, LLM 평가 지표인 BLEU, ROUGE, METEOR로 성능을 평가하였습니다.
표 2에 정리된 결과를 보면, 멀티모달로 학습된 GNN encoder를 업데이트 없이 LLM에 결합한 경우가 가장 좋은 성능을 보임을 알 수 있습니다. 이는 앞서 언급한 것처럼 GNN encoder가 자연어와 분자 구조 정보를 동시에 학습한 지식을 잘 보존하여, 자연어 텍스트를 고려하며 압축한 분자 구조 정보를 LLM에 전달했기 때문입니다.
해당 연구는 화학 분야 특화 LLM의 발전으로 의약화학자들이 AI와 함께 연구를 진행할 시대가 머지않았음을 시사하는 의미 있는 연구였습니다.
언어 공학(LLM)
LLM은 대규모 텍스트 데이터를 학습하여 문장 번역, 요약, 질문 응답 등 다양한 언어 관련 작업을 수행할 수 있습니다. 또한 문맥을 이해하고 텍스트를 생성하는 능력이 뛰어나 다양한 분야에서 활용되고 있습니다.
이번 KCC 2024에서 언어공학 분야의 우수 논문으로 선정된 세 가지 논문을 살펴보기 위해 가져왔습니다.
개체명 기반의 콘텍스트 추출을 통한 의료 분야 검색 증강 질의응답 시스템
ChatGPT를 사용하다 보면 최신 뉴스에 대해서도 이해하고 있는 것을 볼 수 있습니다.
매일 학습을 하는 것도 아닐 텐데, 이런 내용을 어떻게 알고 있을까요? 그 이유는 RAG(Retrieval-Augmented Generation)라는 검색 증강 기법을 사용하기 때문입니다.
웹페이지나 문서 데이터베이스와 같은 외부 소스로부터 관련 정보를 검색하고, 이를 바탕으로 질문에 대한 답변을 생성하게끔 하는 기능입니다. 즉, 정해진 학습 데이터에만 의존하는 것이 아니라 외부 지식을 활용하는 것입니다.
하지만 실제로 사용하다 보면 올바르지 않은 정보나 출처를 제공하거나, 문서를 정확하게 읽지 못하는 현상을 종종 마주할 수 있습니다. 이러한 현상을 완화하기 위해 다양한 시도가 진행되고 있는데, 논문들을 살펴보며 더 자세히 알아보겠습니다.
사용자의 질문이 입력되면, Retriever는 질문과 관련된 문서를 검색하여 가져옵니다. 하지만 가져온 문서들은 매우 길고 많은 정보를 담고 있어 LLM이 처리하기에 비효율적인 경우가 많습니다. 본 논문에서는 의료명 객체에 기반해 이 문서들을 요약한 것을 입력으로 사용하는 방식을 사용했습니다. 또한 의료명 객체가 없는 부분들은 삭제하여 문서를 정제했습니다.
이처럼 질문 의도에 맞춰 문맥을 추출하는 방법은 입력 프롬프트의 토큰 수를 효율적으로 압축하여 계산 비용을 줄이고, 문맥 이해를 높여 환각 문제를 줄일 수 있다고 합니다.

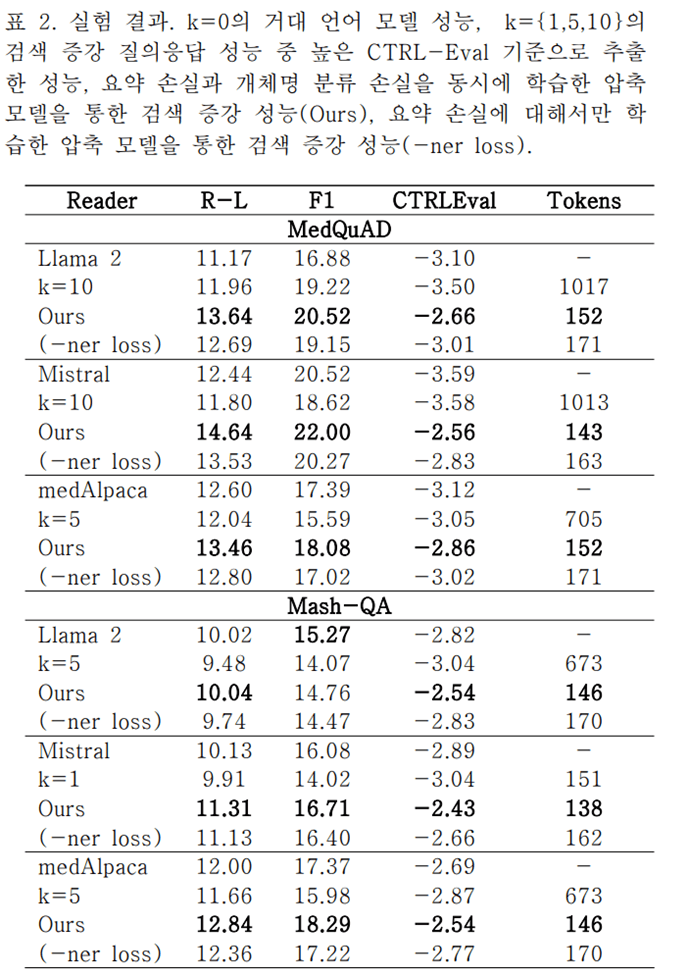
위 표는 MedQuAD와 Mash-QA라는 두 가지 질의응답 데이터셋에 대해 분석한 결과입니다. 텍스트 요약 성능과 품질을 평가하는 지표들에서 기존 언어 모델들에 비해 나은 성능을 보이는 것을 확인할 수 있었습니다. 개체명 인식 기반의 요약 기법을 통해 토큰 수를 줄이고 정확도를 높임으로써, 언어 모델의 성능을 효율적으로 향상시킬 수 있다는 것을 입증한 실험입니다.
LLM의 일반화 능력으로 검생 증강 생성
기존 RAG 접근 방식은 고정된 길이의 검색된 단락을 활용하고, 상위 k개 단락을 참고하여 답변을 생성합니다. 하지만 이러한 방식은 관련 없는 내용을 포함할 가능성이 있어, 잘못된 답변을 유도할 수 있다고 합니다.
이를 개선하기 위해 본 연구에서는 LLM의 강력한 일반화 능력을 활용하여 추가 학습 없이 문장 단위로 관련 없는 내용을 제거하는 방법론을 제안했습니다.

본 방법론은 검색된 단락 내 각 문장에 대해 LLM을 활용하여 "Yes/No" 응답을 유도하는 포인트별(Pointwise) 랭킹 프롬프팅을 사용합니다. 이를 통해 질의와 문장의 관련 정도를 측정하고, 무관한 문장을 제거하여 단락을 정제합니다.
단락 정제는 아래와 같은 과정으로 진행됩니다.
- 검색된 단락을 문장 단위로 분할
- 각 문장과 질의 간의 관련성을 평가하기 위해 LLM에 "Yes/No" 응답을 유도하는 포인트별 랭킹 프롬프팅을 통해 질의와 문장의 관련성 점수를 측정
- 각 문장의 관련성 점수에 따라 사전 정의된 임계값보다 낮은 점수를 가진 문장을 제거
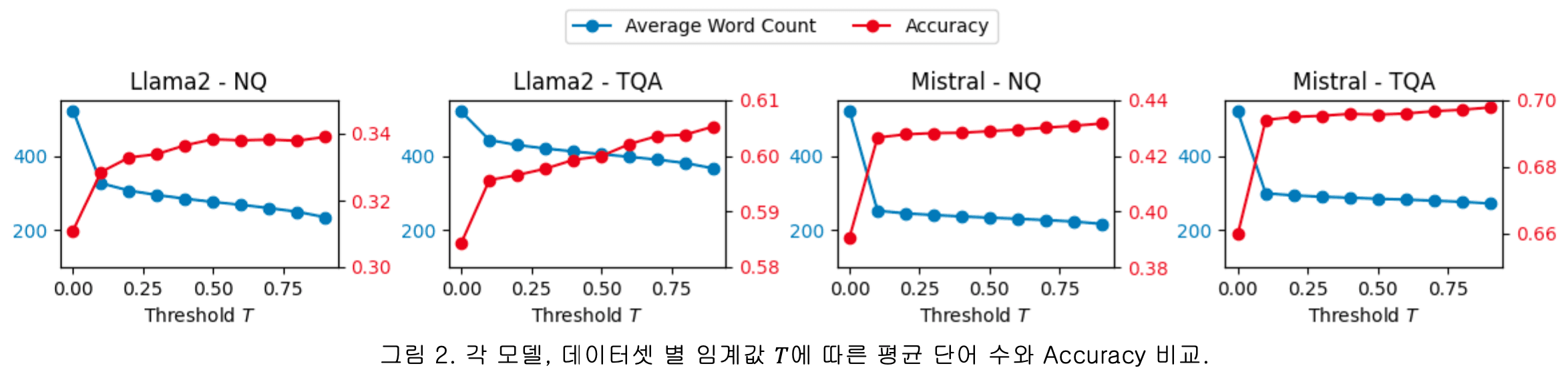
제안된 방법의 성능 평가는 NQ(NaturalQuestions)와 TQA(TriviaQA) 벤치마크 QA 데이터셋을 사용하여 이루어졌습니다. 실험 결과, 기존 RAG 방법에 비해 정확도가 향상되었으며, 단어 수를 줄여 계산 효율성도 개선되었다고 보고되었습니다.
키워드 및 요약 기반 프롬프트를 통한 문서 단위 기계 번역
기계 번역은 한 언어에서 다른 언어로 자동 번역하는 자연어 처리의 하위 분야로, 초기에는 주로 문장 단위로 연구가 진행되었습니다. 하지만 문장 단위 번역은 시제와 주어의 불일치 같은 문제가 발생할 수 있어, LLM과 같이 문맥을 잘 이해하고 일관된 번역을 제공하는 문서 단위의 기계 번역이 중요하다고 합니다.
본 논문에서는 별도의 파인 튜닝 없이 문서 단위 기계 번역 성능을 향상시킬 수 있는 키워드 및 요약 기반 프롬프트를 제안했습니다. 즉, 문서 단위 기계 번역에서 문맥을 효과적으로 전달하기 위해 키워드와 요약문을 프롬프트에 추가하는 방법입니다. 이를 통해 LLM의 토큰 제한으로 인한 문맥 단절을 완화하고, 외부 데이터에 의존하지 않으면서도 성능을 향상시키는 효과를 얻을 수 있습니다.
- 키워드 기반 프롬프트: 중요 키워드를 추출하여 프롬프트에 추가하는 방법입니다. 이를 위해 Named Entity Recognition(NER)과 KeyBERT를 사용합니다. NER은 기관명, 인물, 장소와 같은 엔터티를 추출하며, KeyBERT는 코사인 유사도를 사용하여 문서와 유사한 n-gram 단어를 추출합니다.
- 요약문 기반 프롬프트: 입력 언어와 출력 언어의 요약문을 프롬프트에 추가하여 문맥을 전달합니다. 요약문의 개수에 따라 성능 변화를 비교합니다.
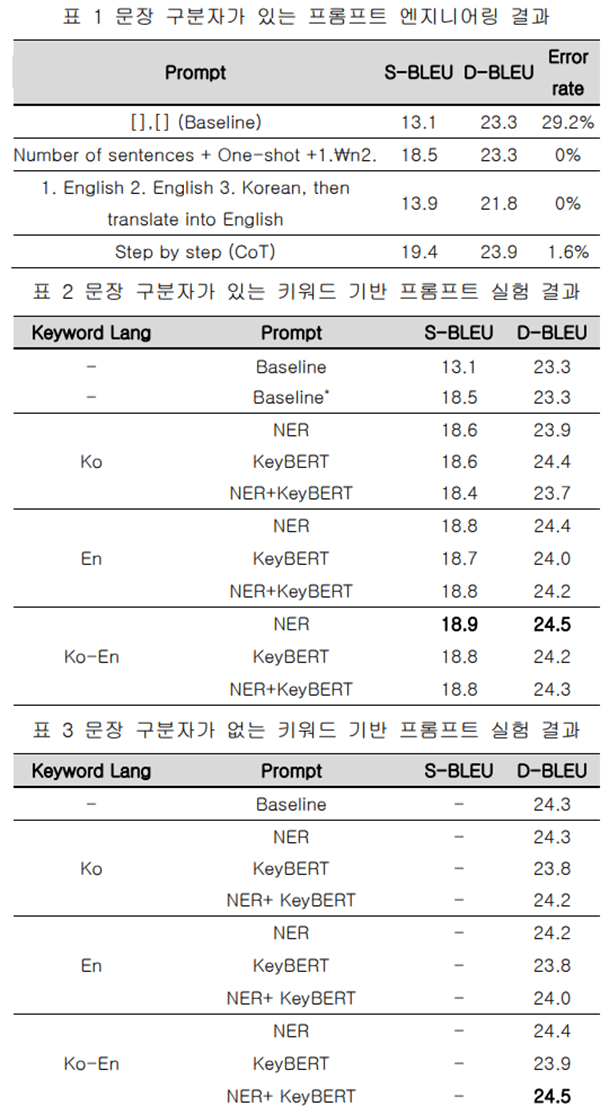
실험은 IWSLT17 Ko-En 데이터셋을 사용하여 진행하였습니다. ChatGPT를 사용해 한국어를 영어로 번역하였으며, S-BLEU와 D-BLEU 지표로 성능을 평가했습니다. 키워드 기반 프롬프트의 경우, 문장 구분자가 있을 때 한국어-영어 NER+KeyBERT 단어 쌍을 사용한 프롬프트가 D-BLEU 24.5로 가장 높은 성능을 보였습니다.
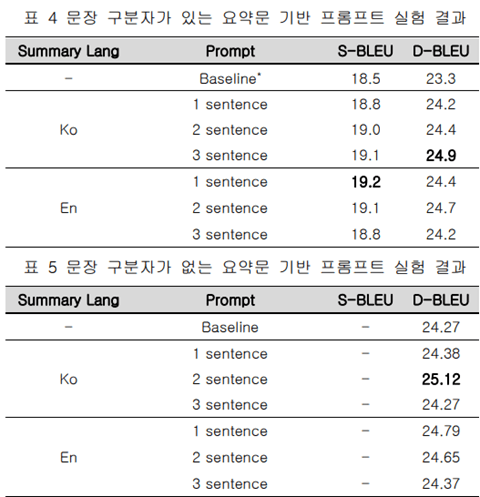
요약문 기반 프롬프트에서는 입력 언어의 요약문을 제공했을 때 D-BLEU가 25.12로 가장 높은 성능을 보였습니다. 이는 입력 언어와 동일한 언어로 요약문을 제공함으로써 문맥 전달이 더 잘 이루어졌기 때문으로 추측됩니다.
언어 모델을 사용할 때, 정확한 결과를 얻기 위해 부가적인 설명을 함께 넣어본 경험이 있으실 텐데요. 실제로 키워드와 요약문을 프롬프트에 넣어주는 것이 답변의 질을 높여준다는 점을 이번 실험을 통해 다시 한번 확인할 수 있었습니다.
AI 모델의 양자화
새로운 기술의 개발보다 그 기술의 보급이 세상에 더 큰 영향을 미친다는 사실을 알고 계신가요?
이번 KCC 2024에서 AI 모델의 양자화(quantization) 적용이 특히 눈에 띈 이유도 바로 이 때문일 것입니다. AI 시대가 시작되고 수년이 지난 지금, 개발된 AI 모델들을 경량화하는 데 많은 연구자들이 관심을 가지고 있다는 점을 실감할 수 있었습니다.
LLM(Large Language Model)과 같이 수십억 개가 넘는 파라미터를 가진 큰 모델은 모든 파라미터를 메모리에 적재해야 하므로 RAM 크기가 매우 중요합니다. 이를 해결하기 위한 기술 중 하나가 양자화(quantization)입니다.
Apple이 올해 발표한 iOS 18에 도입되는 Apple Intelligence를 예시로 이해해 볼까요?

Apple의 Apple Intelligence가 사용하는 생성형 AI 모델의 파라미터는 30억 개라고 합니다. Apple이 온디바이스 AI 모델을 학습할 때 사용하는 파라미터는 float16 데이터 타입으로, 파라미터 하나당 2바이트를 차지합니다.
따라서 30억 개의 파라미터는 60억 바이트, 즉 6GB가 됩니다. 그런데 Apple의 최신 기기인 iPhone 15 Pro의 메모리는 8GB에 불과합니다. 이 경우, 유저가 상시로 AI 모델을 호출하기 위해 항상 6GB의 메모리를 적재해 놓아야 하므로 정상적인 기기 사용이 어려워집니다. 바로 이런 상황에서 양자화 기법이 필요합니다.
양자화 기술은 AI 모델의 성능 하락을 최소화하면서 모델을 경량화하는 것을 목적으로 합니다. 또한, 양자화를 통해 모델의 추론 속도를 증가시킬 수 있다는 장점도 있습니다.
양자화의 종류
양자화의 원리
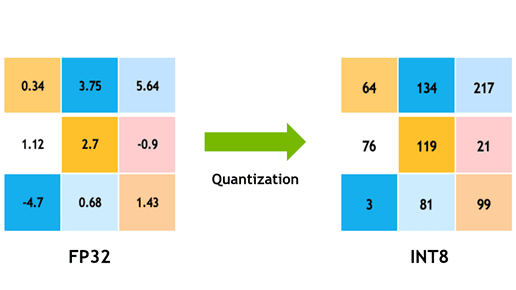
위 그림은 float32의 데이터타입을 int8의 데이터타입으로 바꾸는 예시입니다.
float32의 범위는 -3.4 X 10³⁸부터 3.4 X 10³⁸까지입니다. 그런데 딥러닝의 파라미터가 많다고는 해도 이 범위 모두에 포함되어 있지는 않을 거예요. 따라서 모델의 가중치 값들을 좀 더 작은 크기인 int8의 범위에 할당하고자 하는 것이 양자화의 핵심 아이디어입니다.
그림에서 왼쪽의 양자화하기 전의 데이터의 최솟값은 -4.7이며, 최댓값은 5.64입니다. 이 값들을 int8의 범위(0에서 255까지) 안에 적절하게 매핑하여 양자화한 결과가 오른쪽 그림입니다.
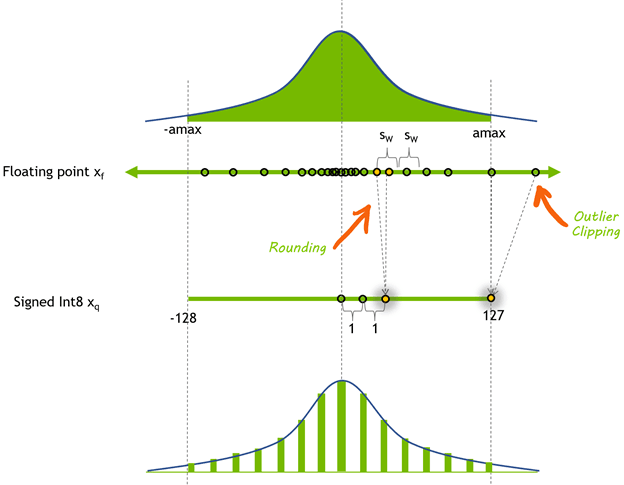
양자화 기법을 적용하는 시점에 따라 양자화의 방식을 나눌 수 있는데, 주로 사용하는 기법 두 가지를 간단하게 살펴보겠습니다.
PTQ (Post Training Quantization)
PTQ는 학습 과정에서는 float32와 같은 크기가 큰 데이터타입을 사용하고, 학습된 가중치 값들에 양자화를 진행시키는 방식입니다. 위에서 소개한 Apple Intelligence에서도 이 방식을 사용한다고 하네요. 이 방식은 이미 학습된 파라미터를 그대로 사용할 수 있다는 것이 장점입니다. 즉 구현이 간단하며 추가적인 학습을 필요로 하지 않기 때문에 널리 이용되고 있습니다.
QAT (Quantization Aware Training)
QAT는 학습을 진행할 때 양자화의 오차를 미리 계산하여 학습에 반영하는 것입니다. 그러니까 forward 과정에서는 가중치 값을 양자화해서 사용하고, 활성화 값 또한 양자화하여 사용하는 것입니다. 그리고 backward 과정에서는 양자화된 가중치 값에 대해서 gradient를 구하는 방식을 통해 양자화 되기전 원래 float32 값을 예측할 수 있도록 학습합니다.
KCC 2024에서 발표된 양자화 연구 소개
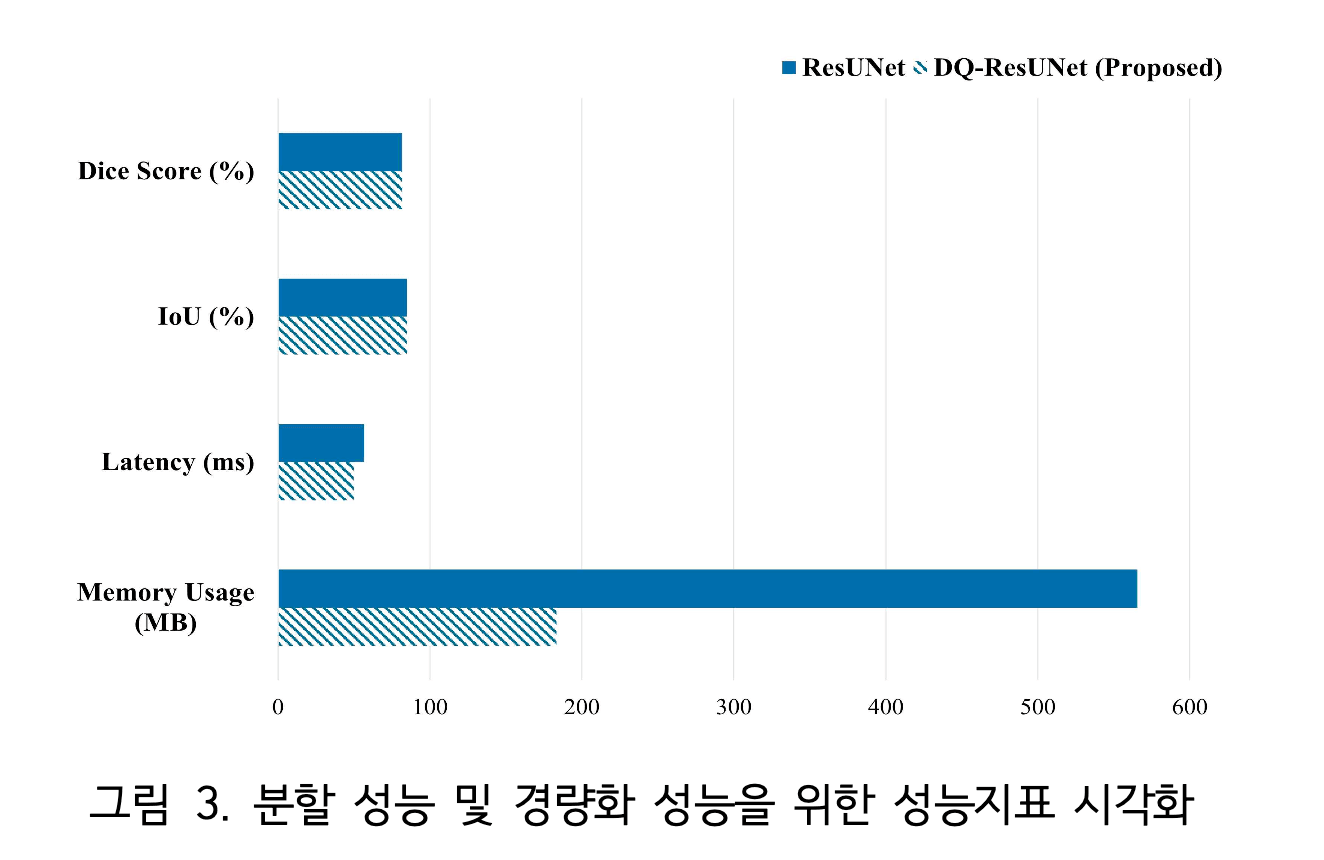
이번 KCC 2024 학회에서 양자화가 사용된 대표적인 연구는 “DQ-ResUNet: 의료 영상 분할의 효율성 개선을 위한 동적 양자화 기반 최적화”라는 연구입니다.
이 연구는 의료 영상 분석에 이용되는 복잡한 인공지능 모델의 경량화 관련 연구입니다. 의료 분야에서 사용되는 컴퓨터는 제한적인 컴퓨터 성능을 지니기 때문에 매우 의미 있는 연구라고 생각되는데요.
해당 연구에서는 PTQ 방식 중의 하나인 동적 양자화 기법을 사용했습니다. 그 결과 약 13%의 추론 속도 향상과 약 208%의 메모리 절감효과를 보였다고 합니다.
그 밖에 HuggingFace 에서도 양자화를 통해 기존의 모델 사이즈를 축소시킨 여러 모델들이 업로드 되어 있으니 관심이 있다면 살펴보시길 바랍니다 [링크].
연합학습(federated learning)과 보안
KCC 2024 다시 보기에서 마지막으로 살펴볼 주제는 연합학습과 보안 분야입니다. 연합학습 (federated learning)이란 여러 사람 또는 기관이 각자의 데이터에 대한 보안을 유지하면서 전체 데이터를 사용해 하나의 글로벌 모델을 개발하는 방법입니다. 많은 경우 하나의 중앙 서버가 존재하여 데이터를 기여하는 각 주체 (”클라이언트”)와 통신하면서 글로벌 모델을 훈련하고, 클라이언트의 요청에 따라 글로벌 모델의 예측 결과를 제공합니다.
일반적인 기계학습이라면 클라이언트들의 데이터를 중앙 서버라는 한곳에 모아 데이터를 한꺼번에 써서 모델을 개발하겠지만, 연합학습의 의의는 보안을 위해 클라이언트들의 데이터를 한데 모으지 않는다는 데에 있습니다. 학습 데이터를 직접 보지 않으면서 직접 본 것과 같은 학습 효과를 내는 것이 연합학습의 연구 주제이죠.
스마트폰의 사용자 데이터를 이용한 다양한 인공지능 기능 개발, 자동차의 운행 데이터를 이용한 자율주행 개발 등 다자의 데이터와 보안이란 두 요소가 조합되는 문제에서 연합학습은 널리 쓰이고 있습니다.
그런 효용성 덕분에 이번 KCC 2024에서도 연합학습과 관련된 연구가 여럿 소개되었습니다. 그중 연합학습에 대한 두 가지 연구와 기업의 보안에 대해 조언하는 논문 한 건을 소개합니다.
연합학습 : 소규모 양성 데이터 및 레이블이 되지 않은 데이터
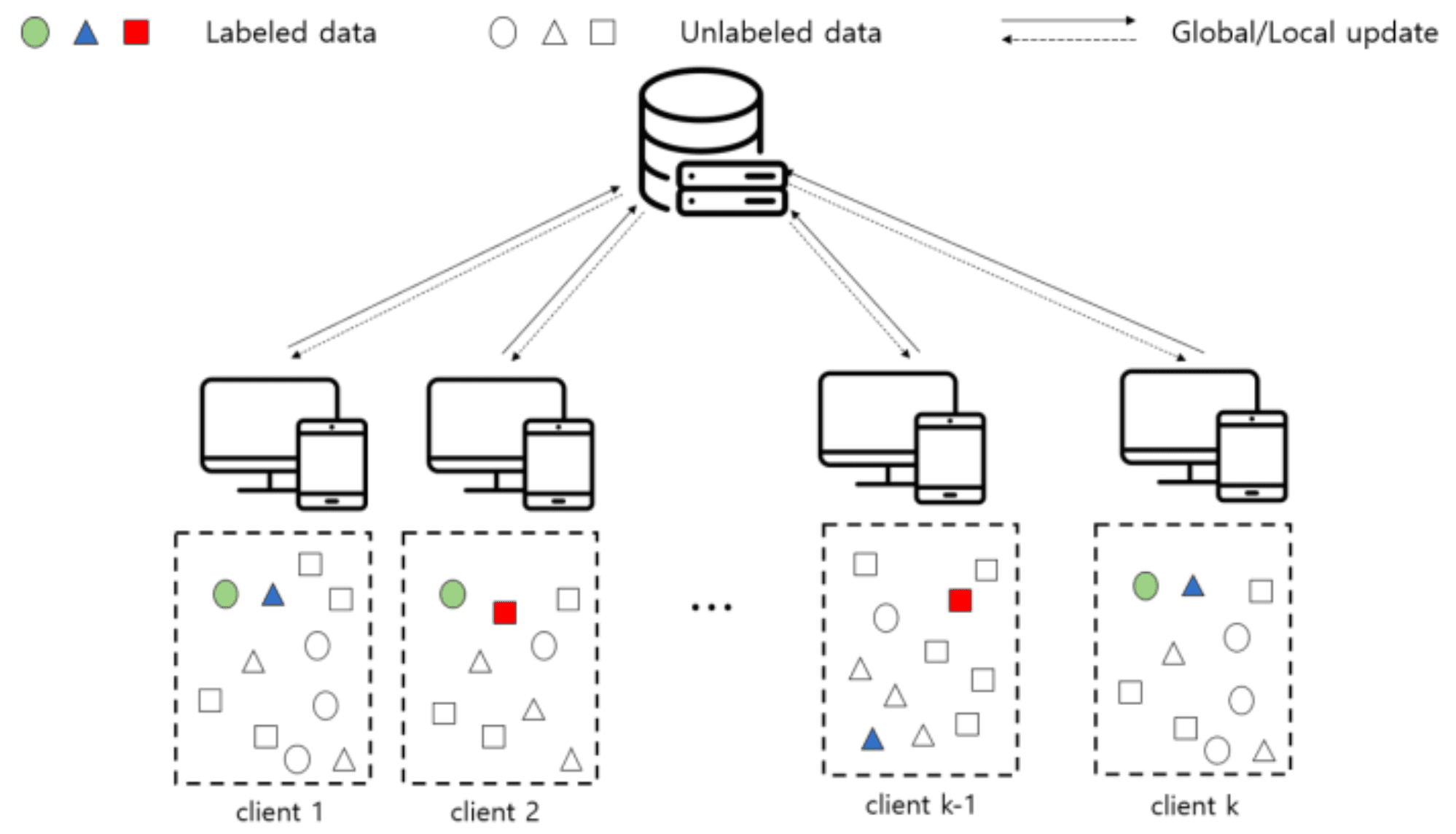
이미지를 여러 가지 클래스 중 하나로 분류하는 모델을 연합학습으로 개발한다면, 클라이언트들이 보유한 이미지들의 클래스 분포는 서로 다를 가능성이 높습니다. 예를 들어 어떤 클라이언트에겐 고양이 사진이 있지만, 다른 클라이언트는 고양이 사진은 하나도 없고 개 사진만 있을 수 있죠. 심지어 각자가 고양이 사진과 개 사진을 매우 적은 양만 가지고 있을 수도 있습니다.
김영현, 박정희 (충남대학교 소속)의 “소규모 양성 데이터 및 레이블이 되지 않은 데이터에 대한 연합 학습”에선 다중 클래스 분류 모델의 연합학습에서 이처럼 클라이언트들이 특정 클래스의 데이터를 전혀 가지고 있지 않으면서 심지어 레이블이 된 데이터의 수도 적은 상황의 해결책을 제시합니다.
관련 상황은 아래 그림처럼 표현해 볼 수 있습니다. 그림에서 각 클라이언트는 서로 다른 클래스에 해당하는 레이블 된 데이터 (예: 고양이 사진이라고 마킹이 되어 있는 사진 데이터)가 매우 적은 양 존재하고, 또한 클라이언트 간에 레이블 된 클래스의 종류가 서로 작은 것을 볼 수 있습니다. 그 외에는 레이블이 되지 않아 어느 클래스인지 알지 못할 데이터들을 다량 보유하고 있습니다.
본 연구에서는 글로벌 모델이 출력하는 클래스 평균을 이용해, 레이블 되지 않은 클라이언트 데이터를 이용하는 방법을 제시합니다. 여기서 클래스 평균의 개념을 알기 위해선 먼저 딥러닝 모델이 데이터를 입력받아 특정 클래스로 분류하는 과정을 알아야 합니다.
딥러닝 모델은 전산화된 이미지, 분자 구조와 같은 데이터를 입력받은 후 해당 데이터의 알짜배기 특징을 뽑아내어 처음의 입력과 다른 수치적 형태로 표현합니다. 이런 중간 표현 상태를 임베딩 (embedding) 혹은 잠재 표현 (latent representation)이라 하죠. 여기서 데이터의 알짜배기 특징이란, 사람 얼굴 사진을 예로 들자면 이목구비의 생김새, 피부색, 얼굴 윤곽 등으로 얘기할 수 있겠지만, 딥러닝 모델이 학습하는 데이터의 특징이란 일반적으로 사람이 해석하기는 힘든 형태입니다. 모델은 입력 데이터를 임베딩한 후 거기 담긴 특징을 이용하여 어떤 한 클래스로 분류합니다.
본 연구에서는 먼저 클라이언트들의 레이블 된 데이터를 글로벌 모델에 입력해 해당 데이터가 속한 클래스의 임베딩을 받고, 그 임베딩을 다시 글로벌 모델에 전송합니다. 이런 연산을 모든 클라이언트가 모든 레이블 된 데이터에 반복하면 각 클래스에 대한 임베딩이 여러 개 준비됩니다. 각 클래스 내에서 임베딩들의 평균을 취하면 그게 바로 해당 클래스의 클래스 평균이 됩니다. 고양이 클래스로 표현하자면 고양이를 나타내는 가장 전형적인 이미지가 클래스 평균이 나타내는 이미지인 셈이죠.
위처럼 클래스들의 평균 임베딩을 얻은 후, 클라이언트의 레이블 되지 않은 데이터들을 클래스 평균을 이용해 가상으로 레이블링합니다. 레이블 되지 않은 데이터를 글로벌 모델에 입력해 임베딩을 받은 후, 그 임베딩과 클래스별 임베딩을 비교해 가장 임베딩이 비슷한 클래스가 해당 데이터가 속한 클래스일 것이라 가정하는 것이죠. 그런 가상 레이블의 신뢰성을 위해 임베딩이 충분히 유사할 때만 가상 레이블을 붙이고, 그렇지 못하면 레이블 되지 않은 데이터인 채로 남겨둡니다.
이렇게 클래스 평균을 이용한 방법은 아래 표에서 보시면 됩니다. 레이블 된 데이터가 적고, 클라이언트 간 데이터 분포가 다른 경우에도 분류 정확도가 향상될 수 있음을 볼 수 있습니다.
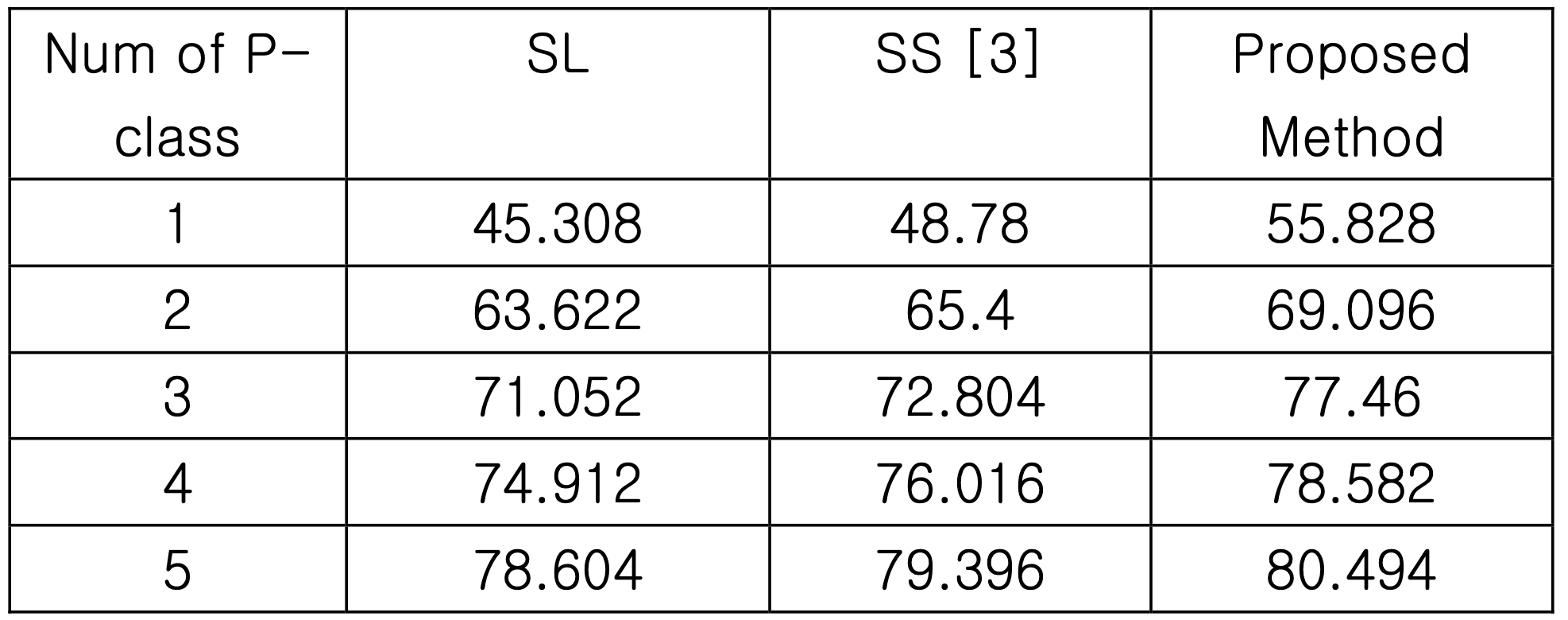
Noise Robust Federated Learning with Active Negative Loss and Representation Regularization
데이터에는 언제나 노이즈가 있을 수 있습니다. 데이터, 특히 레이블에 노이즈가 있는 경우 이는 예측 모델을 개발할 때 문제가 됩니다. 데이터 접근이 제한되는 연합학습 같은 상황에선 노이즈를 예측하고 대비하는 것이 더 제한될 수 있습니다. 예를 들어, 각 클라이언트의 데이터에 서로 다른 원인에서 기인하는 노이즈가 포함할 수 있고, 심지어 무임승차를 꾀하는 클라이언트로부터 잘못 레이블된 데이터를 학습할 수도 있습니다. 이 같은 데이터 노이즈는 딥러닝 모델이 올바른 패턴을 인식하는 걸 방해하고, 결국 예측 정확도를 떨어뜨리게 됩니다.
Girum Fitihamlak Ejigu, 홍충선 (경희대학교 소속)의 “Noise Robust Federated Learning with Active Negative Loss and Representation Regularization”에선 연합학습 상황에서 데이터의 노이즈에 의한 영향을 줄이는 방법을 제안합니다.
노이즈의 영향을 줄이기 위해 본 연구에선 클라이언트 측 학습에 두 가지 장치를 도입합니다. 첫 번째는 active negative loss로, 분류 모델을 훈련할 때 사용되는 일반적인 교차 엔트로피 (cross-entropy) 손실함수에 간단한 정규화(normalization)를 가미하여 손실함수가 레이블의 노이즈에 대해 안정해지도록 만듭니다. 해당 정규화는 [Ma, X. et al. ICML 2020]에서 보고된 방법으로, 원리에 대한 설명은 이곳에서는 생략하겠습니다.
두 번째로는 클라이언트 측 모델에 regularzation을 추가합니다. 딥러닝에서 regularization (정규화라 번역되기도 하나, 그 경우 normalization과 혼동될 수 있다)이란 모델의 일반화된 성능 확보(즉, 과학습 방지)를 위해 일종의 제어 장치를 가하는 것을 말합니다. 본 연구에서는 [Cheng, H. et al. ICLR 2023]의 방법을 사용하는데요, 클라이언트측의 분류 모델에 사영 계층(projection head)을 하나 추가하고, 사영 계층의 출력 표현과 분류 계층의 출력 표현 간에 regularization을 가합니다. 설명이 복잡한데요, 간단히 표현하자면 모델의 학습 용량을 적절하게 제한하여 모델이 레이블의 노이즈까지 암기해버리는 것을 방지합니다.
아래 그림은 클라이언트측 학습 과정에서 본 연구가 도입하는 두 가지 손실함수가 계산되는 과정을 보여줍니다.
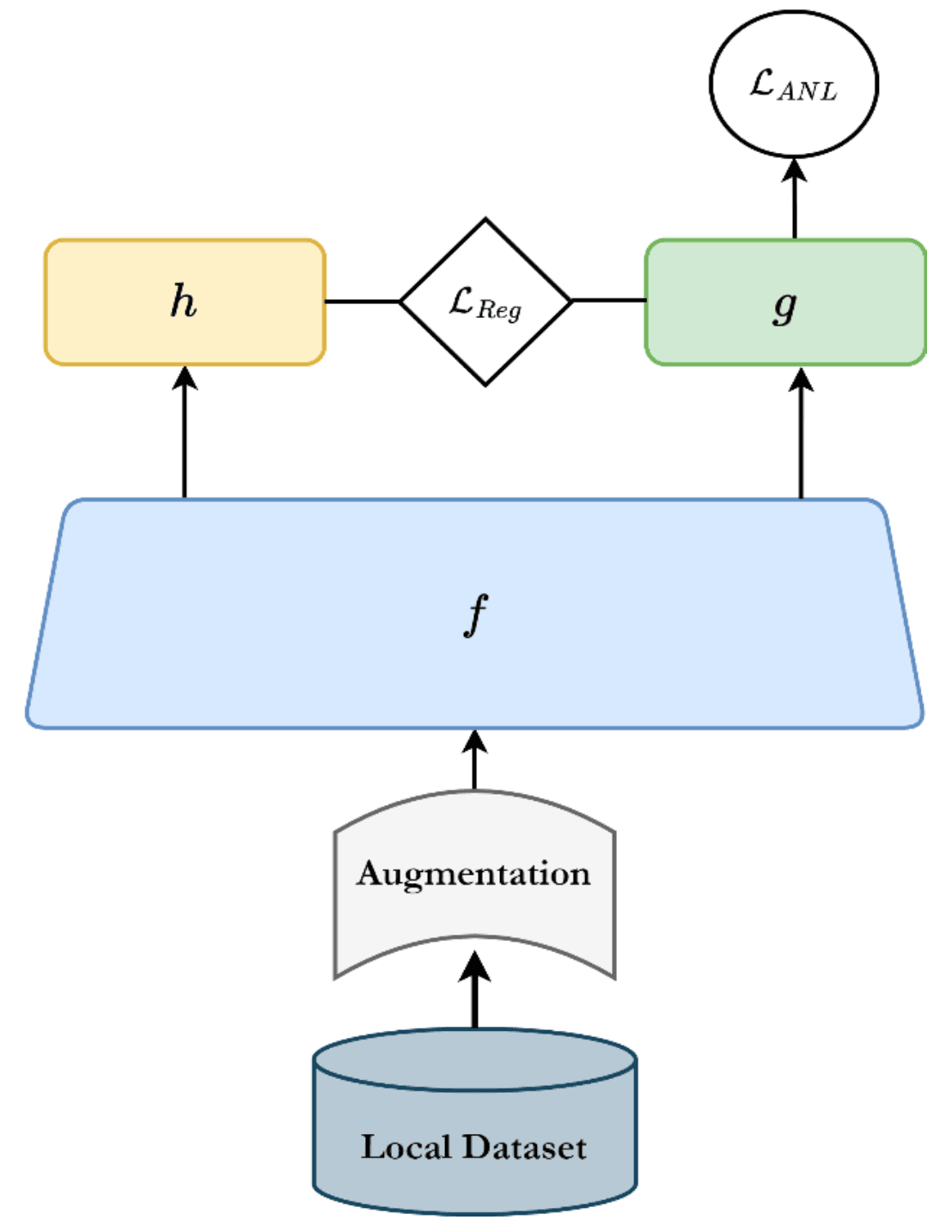
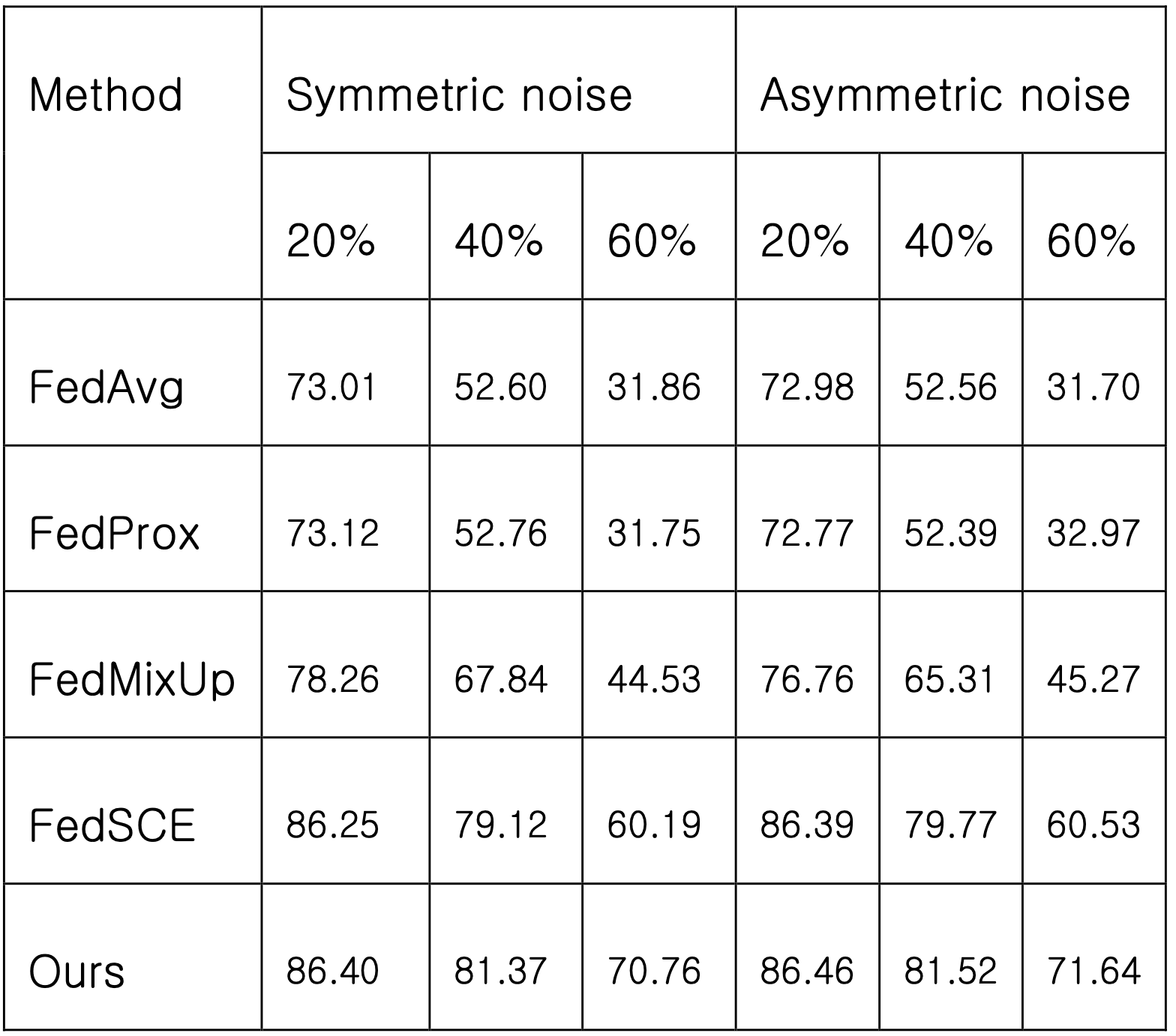
위와 같은 비교적 간단한 변경으로 연합학습 상황에서 레이블에 노이즈가 있을 때 예측 정확도를 올릴 수 있는 것을 보여줍니다. 아래 표는 이미지를 10가지 클래스 중 하나로 분류하는 CIFAR-10 데이터셋을 이용한 실험에서 다양한 강도로 학습 데이터의 레이블이 오염되었을 때 (즉 뒤바뀌었을 때) 연구에서 제안하는 방법이 제일 나은 분류 정확도를 확보한 걸 보여줍니다.
기업 관점에서 SaaS형 클라우드 서비스 사용시 고려할 보안 체크리스트 및 활용 방안 제안
마지막 논문인 김민교, 김민찬, 김현준, 이명학, 남주연, 강성석 (삼성전자 정보보호센터 소속)의 “기업 관점에서 SaaS형 클라우드 서비스 사용시 고려할 보안 체크리스트 및 활용 방안 제안”에선 기업이 서비스형 소프트웨어 (software as a service, SaaS)를 도입할 때 고려해야 할 보안 체크리스트를 제안합니다.
물질을 개발하는 제약 분야나 소재 분야에서 보안의 중요성은 강조할 필요가 없을 것입니다. 그런 만큼 제약사와 같은 곳에서 타사의 소프트웨어, 특히 클라우드 기반의 SaaS와 같은 제품을 도입할 땐 많은 검토 과정을 거치게 되지요.
논문에서는 먼저 아래처럼 SaaS를 이용하려는 기업이 고려할 보안 체크리스트를 제안합니다. 항목들 중 비교적 이해하기 쉬우면서 중요도가 높은 항목을 강조해 보았습니다.
하이퍼랩의 경우 제약사에서 중요시 할 만한 위의 강조된 항목들을 포함하여 다양한 측면에서 보안에 신경 쓰고 있습니다. 기업에 소속되어 하이퍼랩을 포함한 SaaS 도입을 고려하는 분이라면 위 체크리스트를 참고하여 보안 점검을 해보는 건 어떨까요?
| 영역 | 체크 필요 항목 |
|---|---|
| 개인정보 |
|
| 접근통제 |
|
| 로깅 |
|
| 데이터 |
|
| 재해복구 |
|
| 인증 |
|
| 기타 |
|
KCC 2024 다시보기를 마치며
이번 KCC 2024는 히츠의 AI 연구팀원들이 함께 학회에 참석한 만큼 각자 분야를 나누어 논문을 리뷰해보았습니다. 학회의 분야가 컴퓨터·정보과학 전반인 만큼 여기 하이퍼랩 블로그에서 보통 다루지 않는 문제들도 포함되었는데요, 접해보기에 어떠셨나요?
앞으로도 유명 국제학회뿐 아니라 국내학회에서 또 좋은 연구소식이 있으면 전해드리겠습니다.