Google Deepmind AlphaFold 1과 2의 차이점은 무엇일까?


안녕하세요. 히츠의 AI 연구원 배성한이라고 합니다.
지난번 포스트에서는 저희 황상연 팀장님이 AlphaFold-latest에 관해 소개해 주셨습니다. 알파폴드는 2018년 구글 딥마인드에서 처음 세상에 그 모습을 드러낸 후 거듭 놀라운 발전을 보여주며 과학계, 특히 신약 개발 분야에 큰 파급력을 끼치고 있습니다. 알파폴드가 현재 신약 개발 분야에서 필수 기술로 자리 잡은 지금, AI 연구자뿐만 아니라 의약화학자분들도 그 기술에 대해 간략하게라도 이해하시면 인공 지능 신약 개발을 이해하시는 데 도움이 되실 것으로 생각됩니다.
이번 글에서는 현재까지 기술이 공개된 알파폴드 버전 1 & 2에 대해서 AI 연구자의 관점으로 모델의 내부 구조, 데이터 처리 및 학습, 그리고 최종적으로 단백질의 구조를 예측하는 과정에 대해 간략하게 소개해 드리고자 합니다.
Google Deepmind AlphaFold 1의 단백질 구조 예측 방법(feat. MSA,DNN,ResNet)
우선 알파폴드 1부터 살펴보겠습니다. 알파폴드 1은 지난 2018년에 열린 제13회 단백질 구조 예측 대회(CASP13)에 참가하여, 다른 그룹들에 비해 월등히 뛰어난 단백질 구조 예측 성능을 보여주었습니다. 특히 밝혀진 template 구조가 없어서 고전을 면치 못하였던 43개의 도메인 중, 24개 이상에서 0.7 이상의 지표를 기록했습니다. 여기서 사용된 지표는 Template Modeling score(TM-score)로, 이는 예측된 단백질 구조가 실제 구조와 얼마나 유사한지를 평가하는 데 사용됩니다. 알파폴드의 바로 다음 순위를 기록한 그룹이 14개의 도메인을 달성했다는 것만 고려해도 대단한 발전입니다. 그렇다면 알파폴드 1은 어떤 데이터를, 어떻게 학습하여 이러한 성과를 이룰 수 있었을까요?
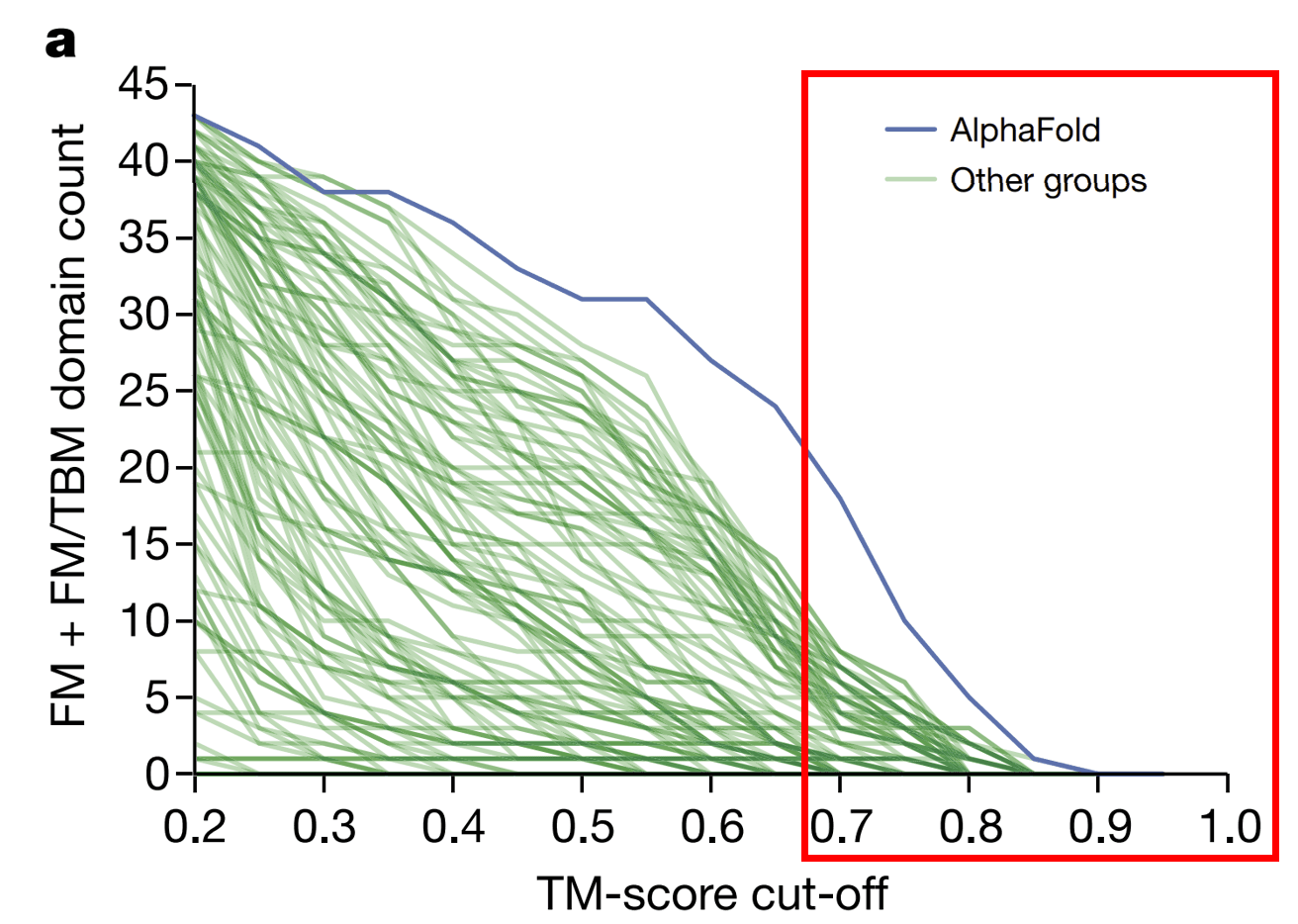
TM score 0.7이상을 기록한 예측 구조들의 수 (빨간색 박스로 표시된 부분)가 알파폴드 1이 압도적으로 많음을 볼 수 있다.
[Adapted from Senior et al. Nature 577: 706 (2020)]
AlphaFold 1이 MSA, DNN, ResNet을 활용하는 이유
우선 알파폴드 1은 단백질의 유사한 서열들을 찾아내어 정렬한 다중 서열 정렬(Multiple Sequence Alignment, MSA)을 학습 데이터로 구성합니다. MSA 데이터는 서열 내 각 아미노산 간의 공진화(co-evolution)에 대한 정보를 포함하고 있습니다. 그리고 진화론적 관점에서도 단백질 구조 형성에 대한 힌트를 제공합니다.
알파폴드 1은 ResNet의 구조를 차용한 심층 신경망(Deep Neural Network, DNN)으로 딥러닝 모델로 구성되어 있습니다. ResNet을 구성하는 합성공 신경망(convolutional neural network, CNN)은 이미지나 MSA 데이터와 같은 2차원 데이터의 공간 정보를 효과적으로 학습할 수 있습니다. 앞서 언급한 것처럼 MSA 데이터는 주어진 단백질 서열 내 아미노산 간의 진화론적인 상관관계를 2차원 공간에 함축한 형태입니다. 따라서 CNN 기반의 신경망은 알파폴드 1에 적합한 구조입니다.
AlphaFold 1이 MSA 데이터를 활용하는 과정
알파폴드 1은 이러한 신경망 구조를 통해 MSA 데이터로부터 각 아미노산의 중심이 되는 탄소 간의 거리와 뒤틀림각의 분포를 학습합니다. 만약 3차원 공간에서 각 아미노산 간의 거리와 뒤틀림각의 분포를 알 수 있다면, 이를 기반으로 단백질의 통계적 퍼텐셜 함수(statistical potential function)를 활용해 구조의 안정성을 평가를 구성할 수 있습니다. 알파폴드 1은 여기에 Rosetta 프로그램을 통해 단백질 구조의 유효성을 평가하는 또 다른 퍼텐셜 함수를 더하여 하나의 최종 퍼텐셜 함수로 통합합니다. 알파폴드 1은 예측한 분포를 기반으로 경사 하강법(gradient descent)을 활용하여, 가장 안정한 형태를 이루는 아미노산들의 뒤틀림각 조합을 찾아냅니다. 이러한 과정을 거쳐 알파폴드 1은 최종 단백질 구조를 예측하게 됩니다.
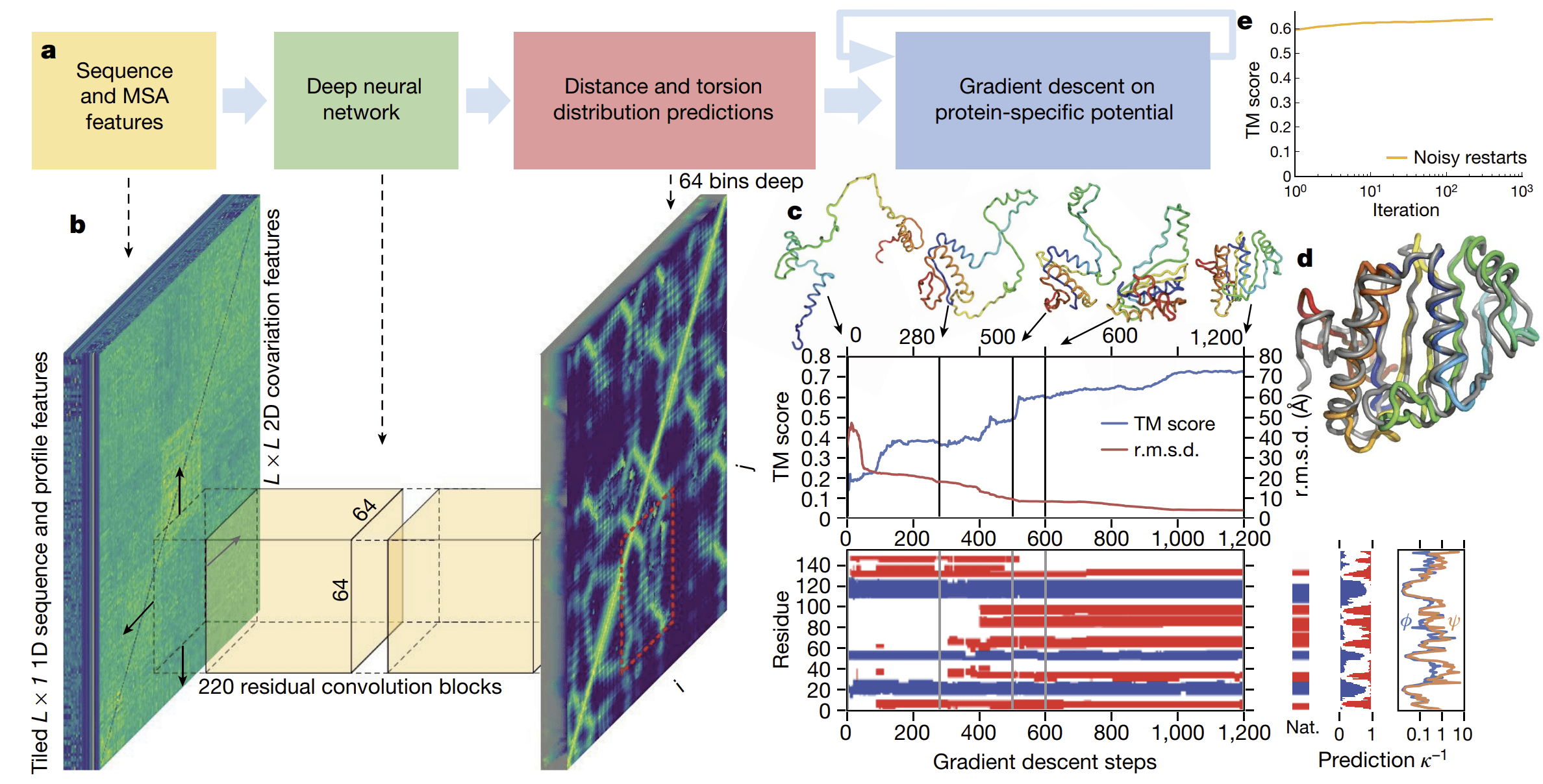
[Adapted from Senior et al. Nature 577: 706 (2020)]Caption
쉽게 보는 AlphaFold 1의 단백질 구조 예측 과정
여기까지 알파폴드 1이 어떻게 단백질 구조를 정확하게 예측하는지에 대해 소개해 드렸습니다.
정리하자면 알파폴드 1은
-
MSA 데이터를 활용한 학습 데이터 구성
-
이미지 분야에서 꾸준히 발전해 온 CNN 네트워크 구조를 차용한 심층 신경망 구축 아미노산들 간의 거리 및 뒤틀림각 분포를 학습
-
네트워크로부터 예측된 아미노산 간의 거리 및 뒤틀림각 분포를 이용한 퍼텐셜 함수 구성
-
3차원 구조를 아미노산들의 뒤틀림각으로 수치화 한 뒤 경사 하강법을 통해 퍼텐셜이 최소가 되도록 뒤틀림각 조합 최적화
와 같은 단계를 통해 높은 정확도로 단백질의 3차원 구조를 예측할 수 있었습니다. 이를 통해 알파폴드 1은 CASP13에서 우승을 차지했으며, 단백질 구조 예측을 위한 AI 시대를 열게 됐습니다.
Google Deepmind AlphaFold 2의 등장 - ResNet를 넘어 Evoformer으로
알파폴드 1의 성공을 거둔 2년 뒤, 딥마인드는 이를 더 발전시켜 더 뛰어난 단백질 구조 예측 성능을 보여주는 알파폴드2를 소개하게 됩니다.
알파폴드 1 출시 이후 2년 여 만에 나온 알파폴드2는 제14회 단백질 구조 예측 대회 (CASP14)에서 전보다 훨씬 월등한 성능을 보여주며 1위를 달성하게 됩니다.
알파폴드 2는 알파폴드1과 비교해 어떤 점이 달라졌기에 이렇게 큰 발전을 이룰 수 있었을까요? 굉장히 다양한 변화점이 있었지만, 이번 포스트에서는 3가지를 중점으로 말씀드리고자 합니다.
-
MSA 기반 학습 데이터의 확장
-
CNN 기반 ResNet에서 attention 기반 Evoformer로 모델 구조의 변화
-
End-to-end 형태로 단백질 구조 예측 방식의 변화
하나씩 살펴보겠습니다.
AlphaFold 2 - MSA 기반 학습 데이터 확장
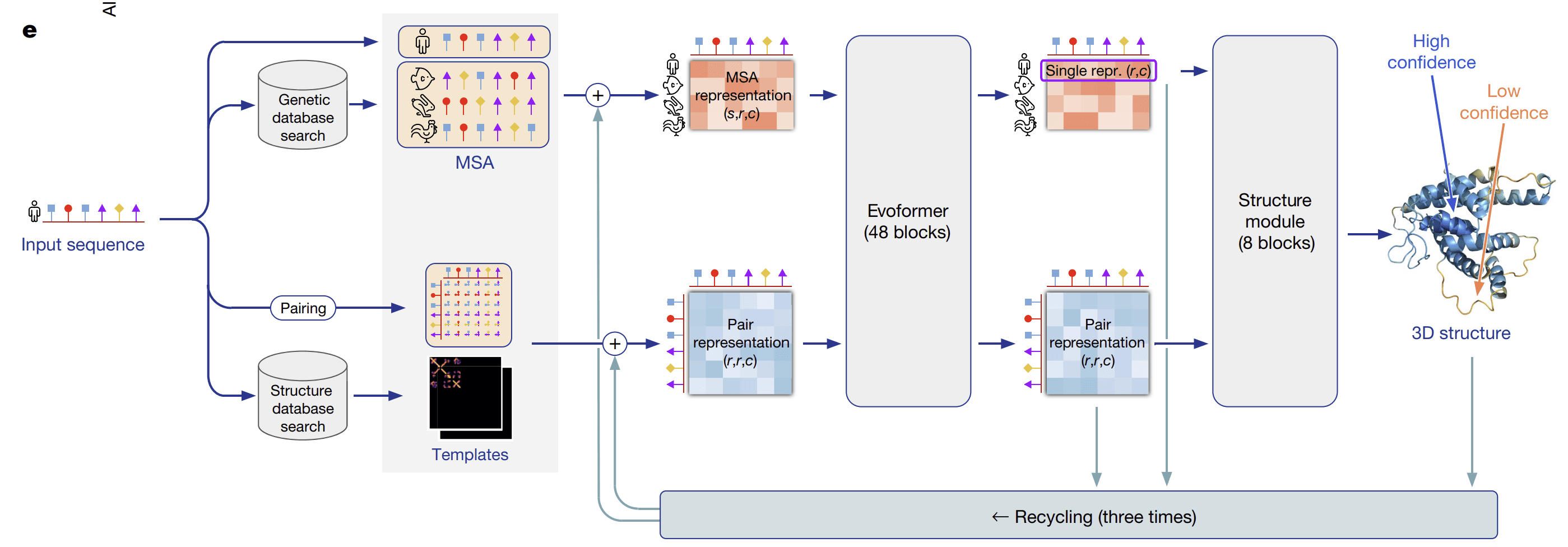
알파폴드 2는 알파폴드 1에서 사용한 MSA 기반 정보를 확장해 두 가지 학습 데이터를 구성하였습니다.
첫 번째는 알파폴드 1처럼 단백질 서열 데이터베이스를 탐색하여 구성한 MSA representation 데이터입니다. 이 MSA 데이터를 활용하여 단백질 구조 데이터베이스를 추가로 탐색합니다.
두 번째는 단백질의 서열과 구조 간의 상관관계에 대한 정보를 제공하는 템플릿(template)을 기반으로 pair-representation 데이터를 구성합니다.
이러한 2가지 MSA 데이터를 통해 최종 학습 데이터셋을 마련합니다.
AlphaFold 2의 네트워크 구조 - MSA를 더 효과적으로 사용하기 위한 Evoformer
알파폴드 1은 2차원 MSA 데이터를 효과적으로 학습하기 위해 CNN 기반 ResNet 네트워크를 구성했습니다.
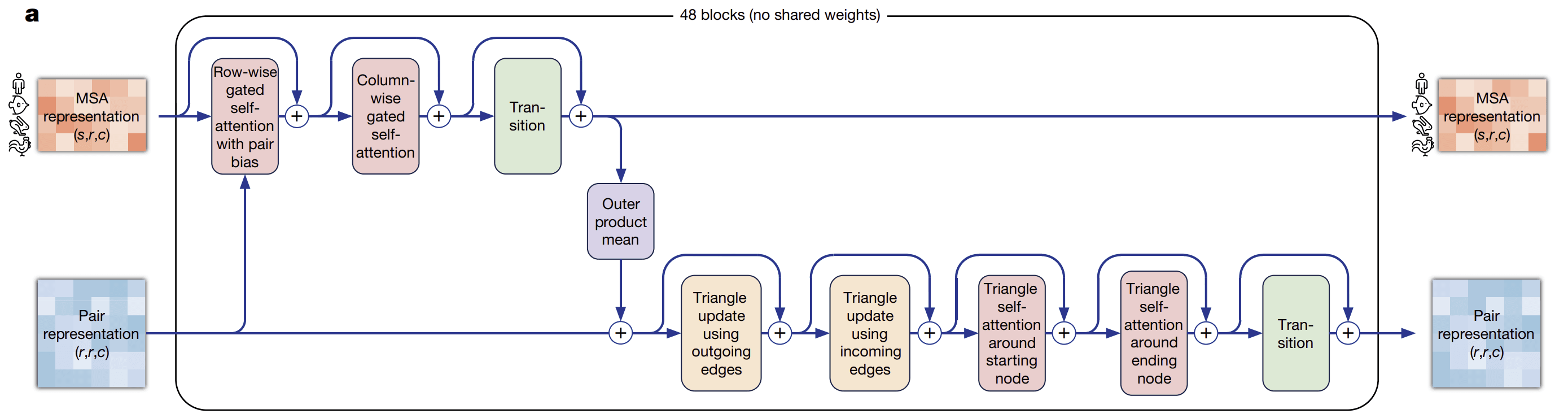
알파폴드 2는 Evoformer라는 새로운 네트워크 구조를 가집니다. Evoformer는 매우 복잡한 내부 구조와 연산 과정을 가지고 있어, 여기서는 간단하게 핵심만 설명 드리고자 합니다.
가장 중요한 핵심은 데이터 내의 구성 요소들 간의 상관관계를 고려하는 ‘attention’ 매커니즘을 활용한다는 점입니다. 이를 통해 서로 다른 단백질 서열 간 상관관계를 학습하고, pair representation 내에서는 입력 단백질 내의 아미노산들 간의 상관 관계를 학습하여 효과적으로 함축된 또 다른 정보를 추출합니다. 또한 Evoformer는 MSA & pair representation 사이에 정보를 교환하는 연산도 포함하고 있어, 두 입력 데이터가 서로를 반영하며 업데이트될 수 있도록 설계되었습니다.
AlphaFold 2의 end-to-end 형식의 단백질 구조 예측
알파폴드 1은 [1. 네트워크를 통한 거리 및 뒤틀림각 분포 예측 → 2. 예측한 분포를 통해 구성한 퍼텐셜 함수의 최적화]라는 두 단계의 분리된 과정을 통해 단백질의 구조를 예측합니다. 이와 달리 알파폴드 2는 입력 데이터로부터 최종 구조 예측까지 하나의 네트워크로 이어지는 end-to-end 형태로 단백질 구조를 예측합니다.
이를 가능하게 해주는 것이 Evoformer 뒷단에 추가된 Structure module입니다. Structure module은 Evoformer를 통해 업데이트된 MSA 및 pair representation을 입력으로 받아, Invariant Point Attention module (IPA module)이라는 attention이 접목된 네트워크를 통해 추가 업데이트를 진행합니다. 이렇게 최종적으로 업데이트된 정보를 바탕으로 각 아미노산마다 유클리디언 변환 (Euclidean Transformation) 행렬을 예측하게 됩니다.
알파폴드 2는 이러한 학습 과정에서 앞서 살핀 예측 데이터를 누적하여 활용합니다. 초기에는 단백질 내 모든 아미노산의 좌표가 원점에서 시작하지만, 학습이 진행됨에 따라 실제 단백질 구조에 가까운 위치로 이동합니다. 아미노산의 좌표 정보(backbone)가 업데이트되면, 이를 기반으로 각 아미노산의 뒤틀림각을 예측하여, 개별 원자의 좌표를 예측합니다.
또한 알파폴드 2는 이렇게 업데이트된 MSA 및 pair representation, 그리고 예측된 구조 정보를 다시 Evoformer와 Structure module에 재입력하는 순환 과정을 반복적으로 수행합니다.
이러한 반복 학습을 통해 전체 네트워크의 예측 정확도를 지속적으로 높이며, 결과적으로 알파폴드 1보다 훨씬 더 정밀한 단백질 구조 예측이 가능해졌습니다.
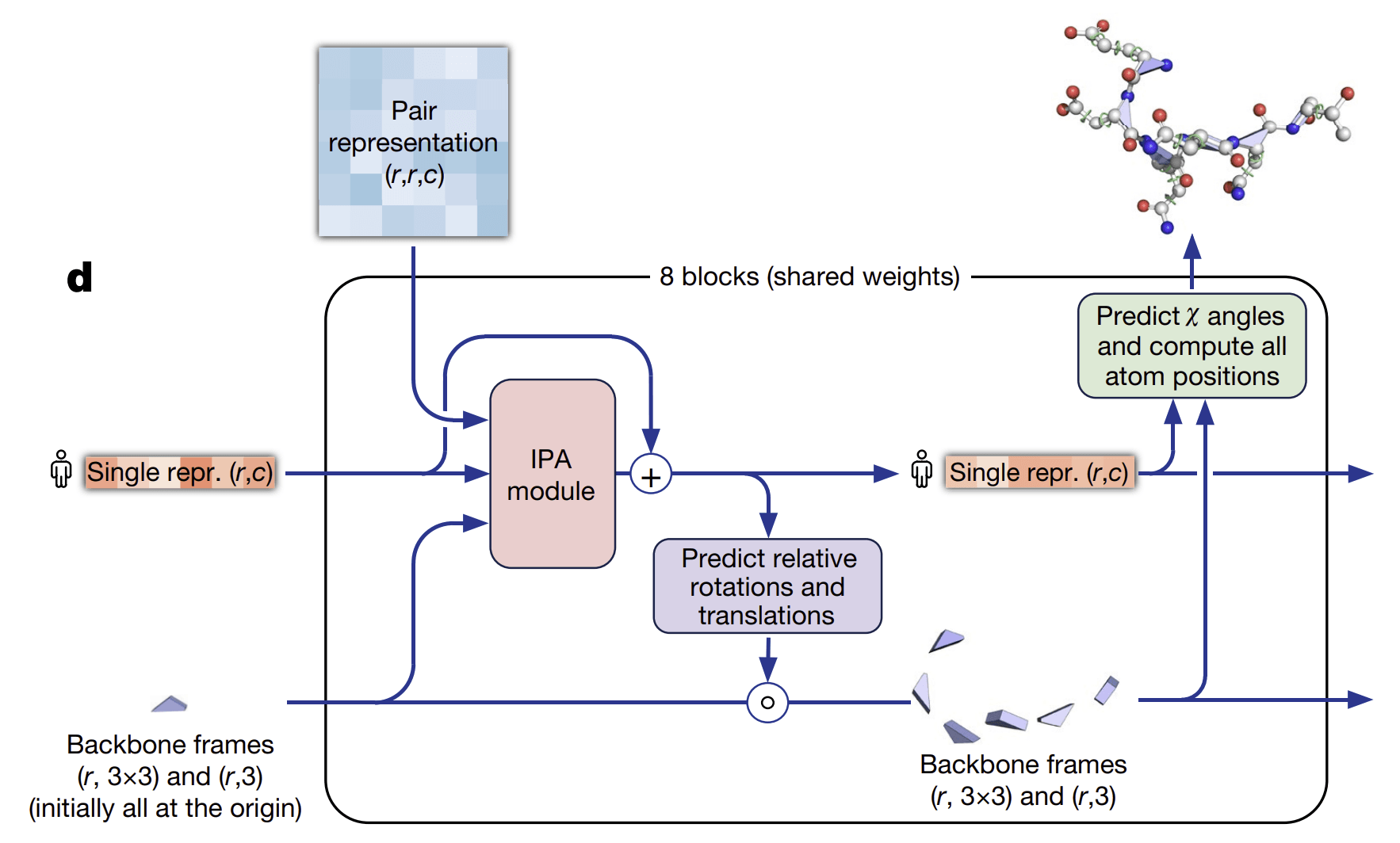
이처럼 알파폴드 2는 알파폴드 1과 비교했을 때, 사실상 전혀 다른 모델이라고 볼 수 있을 정도로 많은 구조적 변화가 있었습니다. 그 결과, 알파폴드 2는 CASP14에서 다른 그룹들을 압도하는 backbone 예측 정확도를 보였을 뿐 아니라, 정밀한 원자 단위의 예측이 요구되는 곁사슬 구조 예측이나, 긴 단백질 서열의 구조 예측에서도 높은 정확도를 보였습니다.
Google Deepmind AlphaFold를 알아야 하는 이유
이번 포스트에서는 지금까지 공개된 알파폴드 1과 2의 기술들을 간략히 살펴봤습니다. 알파폴드는 현시대 AI 분야의 최전선을 개척하고 있는 딥마인드의 연구와 노하우가 집약된 결정체라고 할 수 있습니다.
특히 알파폴드 2는 내부 모델 구조, 연산 방식, 추가 손실 함수, 학습 기법 등 여러 측면에서 알파폴드 1에 비해 큰 변화를 보여줍니다. 이를 정리한 부록(Supplementary information)의 분량만 해도 60페이지를 넘습니다. 아직 공개되지 않은 AlphaFold-latest에는 또 어떤 최신 기술들이 추가되어 있을지 더욱 기대됩니다.
우리는 '미지의 바다'라 불리는 인공지능 신약 개발 분야가 개척되는 순간을 실시간으로 목도하고 있습니다. 이 바다를 항해하는 수많은 개척자들 가운데, 현재까지 가장 앞서 있는 존재는 오늘 소개한 알파폴드일 것입니다.
하지만 대항해 시대의 초창기에 치열한 패권 경쟁이 있었던 것처럼, 알파폴드의 아성에 도전하는 수 많은 경쟁 모델들이 앞으로도 등장할 것입니다. 물론 알파폴드 또한 그 패권을 지키기 위해 지금보다 놀라운 발전을 이어갈 것입니다.
현실적으로 모든 기술들의 흐름을 파악하기는 쉬지 않습니다. 그러나 이 분야의 마일스톤이 되는 핵심 기술들을 놓치지 않고 파악해두는 것만으로도, 인공지능 신약 개발이라는 미지의 바다를 개척해 나가는데 훌륭한 나침반이 되어줄 것입니다.