AI 신약개발과 CADD, 어떻게 다른가요?


AI 신약 개발 기술과 docking은 어떻게 다를까요?
많은 산업분야에서 AI를 적극적으로 도입하고 있습니다. 신약개발 분야도 예외가 아닙니다. 국내 메이저 제약사들 상당수가 직/간접적으로 AI 신약개발을 경험해 보았습니다. 그럼에도 불구하고 AI 신약 개발이 기존 CADD(Computer-Aided Drug Design)와 무엇이 다른지 모르겠다고 하시는 분들이 많습니다. 이번 블로그 글에서는 AI 신약개발과 기존 CADD 기술이 어떻게 다른지에 대해서 적어봤습니다. 특히 현재까지 가장 많이 사용되는 CADD 기술인 molecular docking 기술을 중심으로 설명하겠습니다.
AI(딥러닝)란 무엇인가?
인공지능이란 사람의 지적 능력을 컴퓨터를 통해 구현하는 기술입니다. 굉장히 범용적인 용어입니다. AI를 개발하는 여러 가지 방법이 있습니다. 그중 데이터를 학습시켜 AI를 만드는 방법이 머신러닝입니다. 딥러닝은 머신러닝 방법 중 하나로, 데이터에 내재된 패턴을 계층적으로 뽑아내는 방법입니다. '딥러닝 ⊂ 머신러닝 ⊂ AI'의 포함 관계를 갖고 있습니다. 최근 나온 AI 관련 결과는 99% 딥러닝 기술을 이용해서 구현됐다고 봐도 무방합니다.
Docking과 AI신약개발(딥러닝)의 차이
Docking의 핵심은 scoring function입니다. 많이 사용되는 Scoring function들은 물리식과 empirical parameter들로 구성되어 있습니다. 딥러닝 모델들도 parameter들이 있지만 몇 가지 중대한 차이가 있습니다.
- Docking의 parameter들은 연구자들이 정합니다. 간단한 fitting 기술과 연구자들의 직관을 기반으로 실험값을 잘 맞출 수 있도록 연구자들이 parameter를 정합니다. 예를 들면 약물과 단백질 사이 결합에는 수소결합이 중요함을 인식하고 수소결합을 모델링할 수 있는 물리식과 이 식을 고안하고 식에 포함되는 소수의 parameter들을 설정합니다. 반면에 AI의 경우 이러한 parameter들이 목적함수를 만족하기 위해 학습과정 중에 자동으로 학습됩니다.
- Parameter 수가 다릅니다. Scoring function은 10-20개 정도의 parameter로 구성되어 있습니다. 딥러닝의 경우 parameter 수가 적어도 10만 개 이상입니다. Scoring function은 연구자들이 물리적 현상을 고려하여 정하기 때문에 숫자의 한계가 있을 수밖에 없습니다. 반면에 딥러닝은 고도화된 최적화 알고리즘과 컴퓨팅 자원을 활용하기 때문에 수십만(수십억 개까지도) 개의 parameter도 최적화할 수 있습니다.
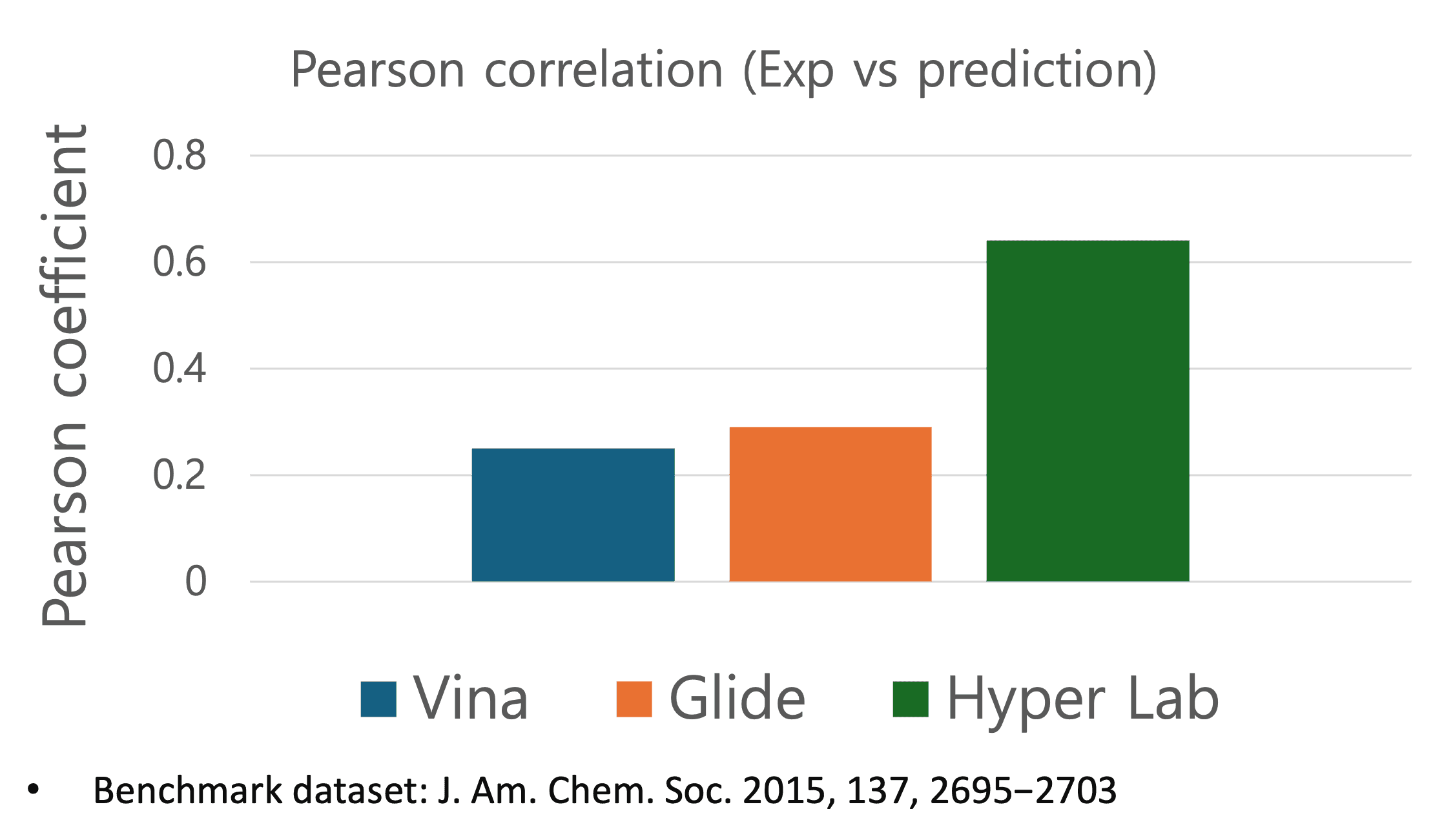
- 이러한 이유들로 성능 차이가 발생합니다. 많은 연구결과들에서 딥러닝 모델이 docking보다 우수한 성능을 보인다는 연구결과를 보여주고 있습니다. 대표적으로 아래 논문들이 있습니다.
발전가능성
Docking은 활발히 연구되고 있습니다. 하지만 아쉽게도 큰 접근법은 십 수 년 전과 그대로입니다. 실험 연구자들이 주로 사용하는 상용 docking 소프트웨어들의 핵심 원리는 처음 등장했던 20년 전과 큰 차이가 없습니다. 하지만 딥러닝은 다릅니다.
-
알고리즘이 빠르게 발전하고 있습니다. 이를 바탕으로 알파폴드 3와 같은 모델들이 계속해서 제안되고 개선되고 있습니다.
-
데이터가 꾸준히 증가하고 있습니다. 약물-단백질 상호 예측 딥러닝 모델 개발에 흔히 사용되는 PDBbind의 경우 매년 약 10%씩 데이터가 늘어나고 있습니다. 데이터가 증가할 수록 딥러닝 모델의 성능은 자연스럽게 향상됩니다. 이런 점들을 봤을 때 성능 차이는 계속해서 벌어질 가능성이 높습니다.
| 년도 | PDBbind 데이터 수 |
|---|---|
| 2020 | 23,496 |
| 2019 | 21,382 |
| 2018 | 19,588 |
| 2017 | 17,900 |
왜 아직까지 AI 신약 개발 기술보다 docking이 더 많이 사용될까요?
첫 번째로 성능 향상 폭이 신약개발 연구자들에게 혁신적으로 다가올 만큼 크지 않기 때문이라고 생각합니다. 피처폰과 스마트폰의 차이보다는갤럭시 S20과 S24 정도의 차이라고 할까요? 그렇기 때문에 도입 속도가 생각만큼 빠르지는 않습니다.
두 번째는 좋은 AI 신약 개발 소프트웨어가 아직 없습니다. 저는 2번째 이유가 더 크다고 생각하는데요, 논문으로 나왔다고 해서 연구자들이 바로 이 기술을 연구에 사용할 수 있는 건 아닙니다. 연구자들이 직접 사용하기 위해서는 접근성이 높고 사용하기 쉬운 소프트웨어가 필요합니다. 공동연구나 기술 서비스는 시간이 오래 걸리고 외부에 있기 때문에 긴밀하게 적용하기 어렵습니다. 가장 좋은 방법은 연구자들이 직접 써보고 비교해 보는 것이겠지요.
만일 기존 docking 보다 쓰기 쉽고 정확한 AI 신약개발 소프트웨어가 있다면 써보시겠습니까? 지금 바로 하이퍼랩을 통해 docking과 성능도 비교해보고 AI신약개발을 경험해보시길 바랍니다.