Google's Next-Gen Deep Learning Architecture, Titans Takes on the Transformer Dynasty


Hello! I’m Sung-han Bae, a researcher from Team 1 of Hitz’s AI Research Division.
Are you familiar with deep learning architectures? The term might sound a bit unfamiliar, but we’re already reaping the benefits of this technology in countless aspects of our daily lives. For instance, when chatting with a chatbot, using an automatic translator, or when a self-driving car recognizes the road, it’s a “deep learning architecture” working behind the scenes. Today, I’d like to introduce you to the Transformer, a cornerstone of this field, and Titans, a newly emerging architecture that’s gaining attention.
What is a Deep Learning Architecture?
A deep learning architecture refers to the structural blueprint of a neural network. It encompasses decisions about how many layers to stack, how to connect them, and which operations to use. Think of it like designing a house: a sturdy and efficient structure leads to a high-performing model. Even with the same data, the way a model learns and its expressive power can vary greatly depending on the architecture’s design. Simply put, a deep learning architecture is about crafting the "brain structure" that determines how a model takes in, processes, and remembers information.
Historically, the emergence of new architectures has often marked leaps in performance and opened doors to new applications. For example, Convolutional Neural Networks (CNNs) revolutionized image processing, while Recurrent Neural Networks (RNNs) laid the groundwork for handling sequence data like natural language with deep learning. In this way, advancements in architecture have been a driving force behind the rapid progress of deep learning technology.
Deep Learning Architecture - The Advent of the Transformer
In 2017, Google researchers introduced the Transformer in their paper “Attention Is All You Need,” marking a departure from RNNs. Unlike RNNs, the Transformer leverages an attention mechanism that enables parallel processing, allowing it to consider relationships between all pairs of elements (tokens) in a sequence simultaneously. This breakthrough enabled the model to capture the long-range context in sentences while speeding up training, sparking a revolution in natural language processing (NLP). The arrival of the Transformer was akin to transforming a meeting where people spoke one at a time into one where everyone could hear each other in real time.
The Transformer fundamentally changed how deep learning models process data and understand context, laying the foundation for today’s AI innovations. It led to record-breaking performance improvements in NLP tasks like translation, document summarization, and question-answering. Large-scale pre-trained language models (LLMs) such as BERT and GPT were built on the Transformer architecture. Beyond language, the Transformer has been adapted to fields like image processing (e.g., Vision Transformers, or ViT) and multimodal applications, establishing itself as a standard across AI.
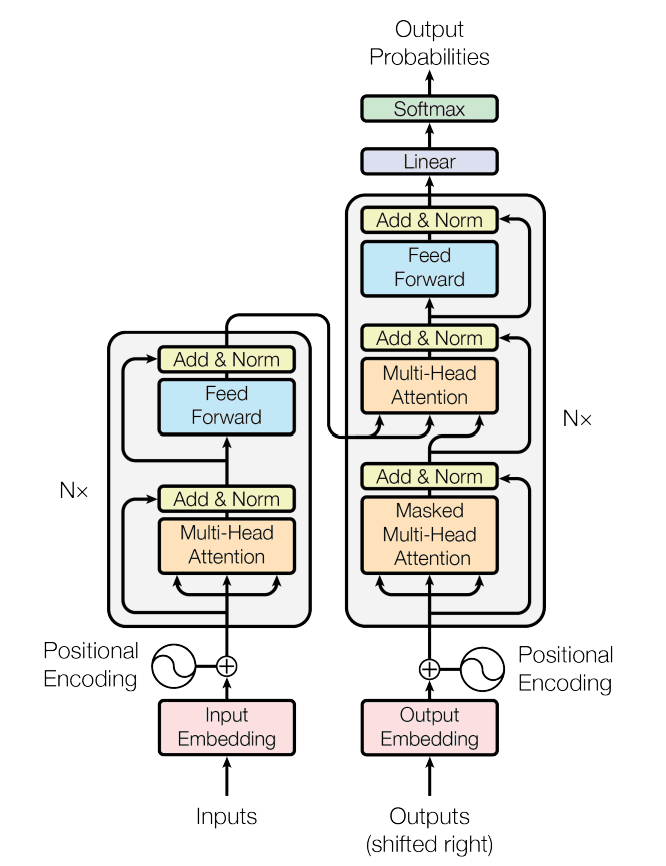
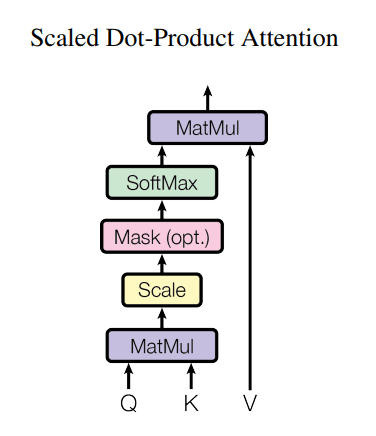
Deep Learning Architecture - Limitations of the Transformer
While the Transformer is a groundbreaking model, it comes with inherent limitations, particularly in computational complexity and long-term dependency handling. These constraints make it insufficient on its own for tasks involving very long sequences or requiring continuous real-time learning. Below, we’ll explore two key limitations of the Transformer.
Transformer Limitation 1: Computational Complexity of the Attention Mechanism
As input sequence length grows, the Transformer’s computational demands increase exponentially, and its ability to capture context is structurally limited.
The Transformer’s core, the attention mechanism, calculates similarity scores between all token pairs in the input sequence, resulting in a computational complexity of $O(n^2)$ with respect to input length $N$. For example, doubling the input length quadruples the attention computation, and as sequences grow longer, memory and computational costs skyrocket.
This structural limitation means a typical Transformer can usually process contexts of a few thousand to tens of thousands of tokens. Beyond that, handling longer sequences becomes impractical due to resource and memory constraints. Yet, real-world applications often require much larger contexts—think video understanding, long-term stock price prediction, or genomic analysis, which involve sequences of hundreds of thousands of tokens. The Transformer alone struggles to address these tasks.
As a result, the Transformer’s attention structure is inefficient for long inputs, capping the size of the context window it can effectively process. To overcome this, various efficient attention techniques have been proposed, such as sparsifying the attention matrix to reduce unnecessary computations or approximating the softmax function. The Linear Attention structure, introduced in 2020, replaces attention computations with kernel functions, theoretically reducing complexity to near $O(n)$.
Transformer Limitation 2: Difficulty Handling Long-Term Dependencies
By design, the Transformer struggles to fully retain and leverage long contexts, a weakness that remains a key critique of Transformer-based AI.
Within a range of thousands to tens of thousands of tokens, the Transformer’s self-attention excels at directly referencing relationships between distant sequence elements, far outpacing RNNs in long-term dependency learning. However, this is limited to a fixed context window per model—typically 2048 or 4096 tokens—beyond which earlier information is inaccessible.
For example, processing an entire novel with a Transformer requires splitting it into chunks, with earlier content unavailable when handling later sections. This makes it hard to capture long-term dependencies, like a plot point from Chapter 1 resolving in Chapter 20. The Transformer effectively operates as a short-term memory system.
RNNs, with their recurrent hidden states, could theoretically handle unlimited sequence lengths, but older information often fades due to vanishing gradients. The Transformer overcomes these RNN limitations with parallelism and attention, yet it still cannot retain information beyond its context window. Techniques like summarizing and passing past information have been studied, but they introduce information loss or require retraining at each step. Tasks like complex question answering, multi-document summarization, or genomic analysis with millions of tokens demand vast contexts that the Transformer alone cannot adequately handle.
Deep Learning Architecture - The Rise of Titans
To address the Transformer’s limitations, Google researchers introduced a new architecture in late 2024 via the paper Titans: Learning to Memorize at Test Time—Titans. Inspired by the interplay of short-term and long-term memory in human reasoning, Titans combines a neural network-based long-term memory module with the Transformer, creating a novel deep learning architecture.

A Human-Like Memory Architecture - Titans
Titans was developed to efficiently maintain long-term memory. As noted, Transformers cannot utilize information beyond their context window, often missing key details in long contexts. Google researchers tackled this by introducing a neural network-based memory module. Past attempts like Neural Turing Machines, Memory Networks, or RNN long-term states aimed to use external memory but faced challenges like difficult training or slow performance.
The Titans team asked, “What if a model could remember the past on its own and retrieve it when needed?” To this end, they introduced Neural Memory, a long-term memory network that learns during both training and inference. Using online meta-learning, Neural Memory dynamically adapts to new inputs as they arrive.
This allows the model to retain new information during testing, moving beyond reliance on fixed training data and enabling effective handling of changing data or very long sequences. This concept mirrors how humans store new facts in long-term memory upon encountering them.
Core Features of Titans
Titans’ architecture is distinguished by its integration of three memory systems.
First, it uses the Transformer’s attention mechanism as short-term memory, precisely modeling relationships within the current context window. Added to this is a long-term memory component, the Contextual Memory module. Unlike RNN hidden states that compress past data, Contextual Memory learns and stores past key-query pair information in a separate module, retrieving it as needed. This module continuously updates as it processes past inputs, maintaining persistence in accumulating prior information.
Titans also include Persistent Memory, another long-term memory module composed of task-independent trainable parameters. This stores prior knowledge or global context, appended as special tokens to each input sequence’s start, enabling the model to leverage general knowledge or task-specific background information.
Titans are designed to parallelize these short- and long-term memory modules for organic, rapid learning. Unlike RNNs, which sequentially process the past and struggle with parallelization, Titans divide the time axis into chunks, processing memory updates in parallel across segments. Tensor operations and matrix multiplications are computed in parallel per chunk, optimizing training on GPUs/TPUs. This allows Titans to learn long-term memory without significant delays during training, while lightweight memory updates enable fast inference.
In summary, Titans integrates short-term attention, long-term memory modules, and persistent memory parameters into one architecture, enabling learning and inference across short and long ranges. It combines RNN-like memory with Transformer-like parallel processing.
Comparing Titans and Transformers
Let’s now compare Titans with the Transformer to highlight their differences and advancements. While both target sequence modeling, they differ in internal structure and operation, impacting performance, scalability, and functionality. We’ll also cover performance differences validated by experimental results.
Structural and Functional Differences
Architecturally, the Transformer is a single-path network of alternating attention and feed-forward layers. Titans, however, resembles a dual-path system with added memory modules. It retains the Transformer’s attention-based core while incorporating a parallel long-term memory pathway. Titans offer multiple implementation variants based on how it integrates current-context attention with long-term memory.
- MAC, MAG, MAL
In the MAC (Memory as a Context) structure, input sequences are split into fixed-length segments. When processing each segment, the model retrieves relevant information from accumulated memory to provide additional context during attention computation. The attention module considers both the current segment and a memory-provided past summary to generate output, which then updates the memory.
The MAG (Memory as a Gate) variant splits processing into two streams: one updates the long-term memory module, while the other uses sliding window attention. The outputs are combined via a gating mechanism.
Finally, the MAL (Memory as a Layer) structure treats the memory module as a layer, sequentially passing input plus Persistent Memory through Contextual Memory before feeding the result into the attention layer. Across these variants, Titans consistently feature explicit memory modules—unlike the Transformer—complementing attention by handling long-range information it cannot process.
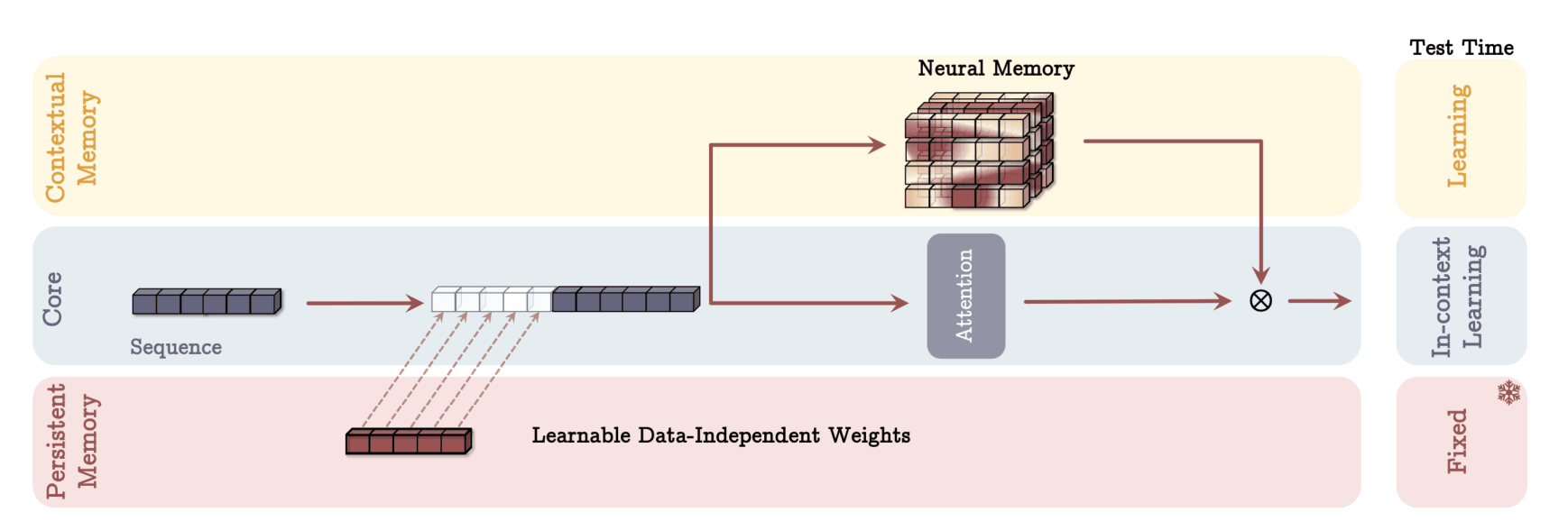
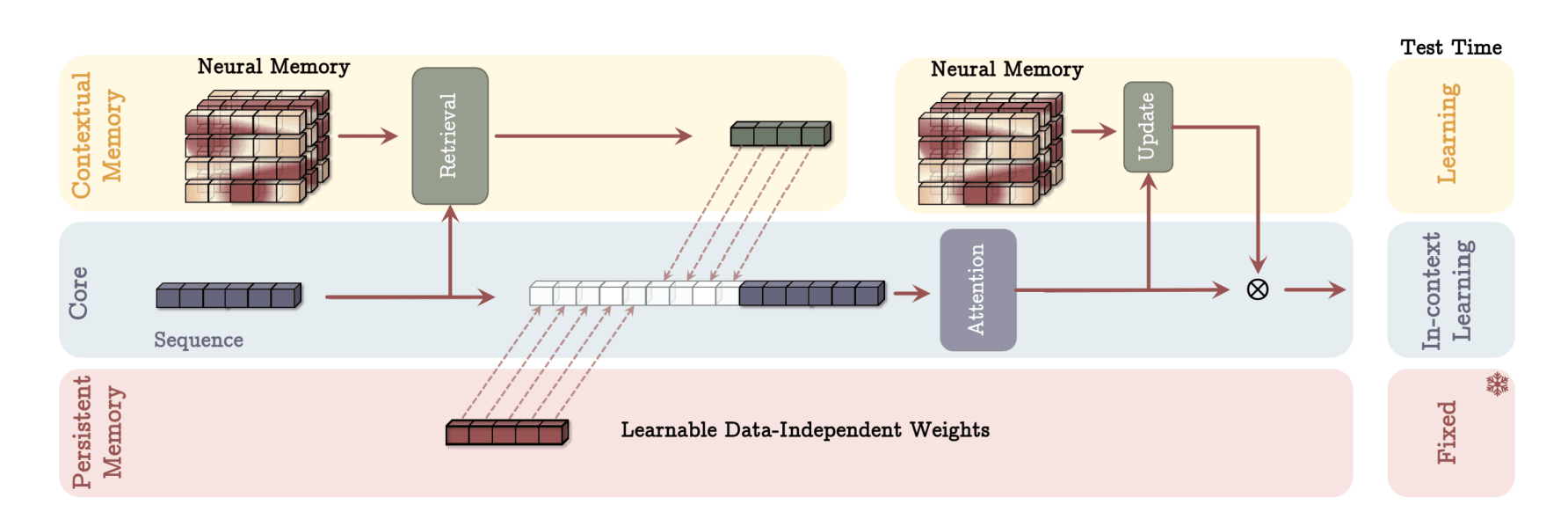
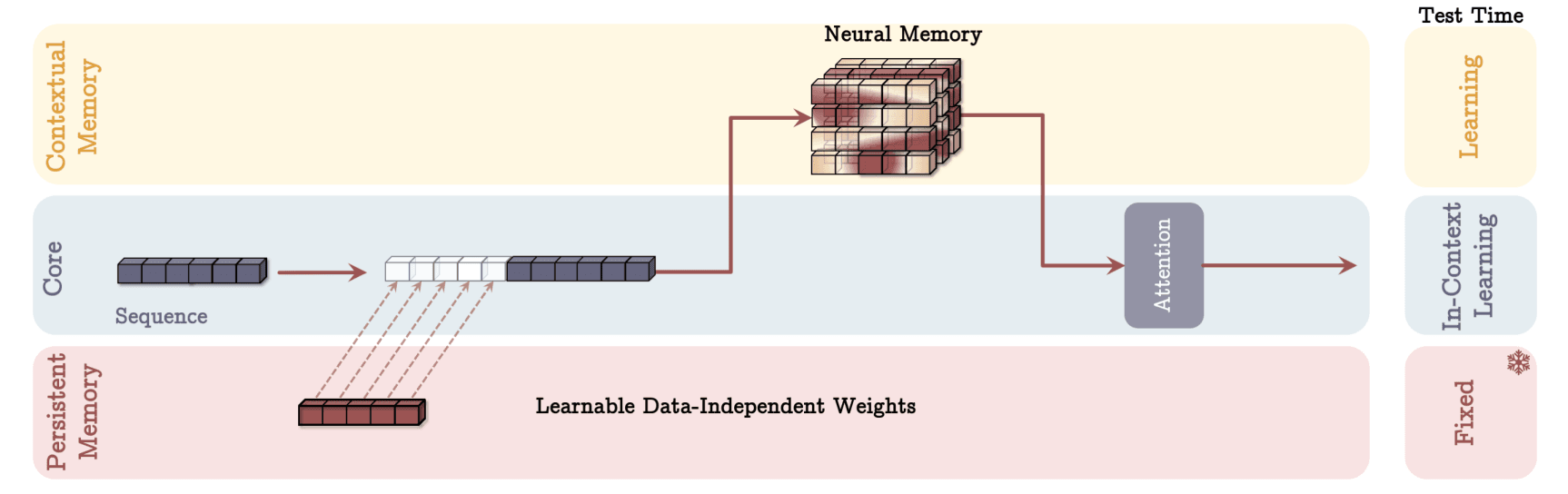
- Persistent Memory: A Repository of Prior Knowledge
Another notable feature is Persistent Memory. As described, it consists of trainable parameters holding task-specific global knowledge, giving the model a head start with “background knowledge.” This can be advantageous over Transformers, which must learn everything anew each time. For instance, in commonsense reasoning, Persistent Memory stores general knowledge, referenced with each question or sentence to aid inference. The Titans paper notes that this mitigates attention’s tendency to overly focus on sequence beginnings, enhancing model stability.
- Titans’ Efficiency and Scalability: Handling Long, Complex Inputs
In terms of computational complexity and scalability, Titans includes the Transformer’s attention module, so its worst-case complexity is $O(n^2)$. Practically, however, it processes very long sequences by referencing only parts via attention and delegating the rest to memory pathways, achieving near-linear scaling. For example, in the MAG structure, sliding-window attention uses small windows, with long-term memory handling information beyond them, keeping the attention scope constant despite longer inputs. Titans can thus efficiently handle contexts exceeding 2 million tokens without performance degradation. In contrast, Transformers struggle with tens of thousands of tokens due to memory shortages or delays, and scaling them up often degrades performance. Titans excels in scalability, using less memory and offering inference speed advantages by reusing updated long-term memory rather than comparing each token to all past ones, as Transformers do.
Performance and Innovative Functionality Comparison
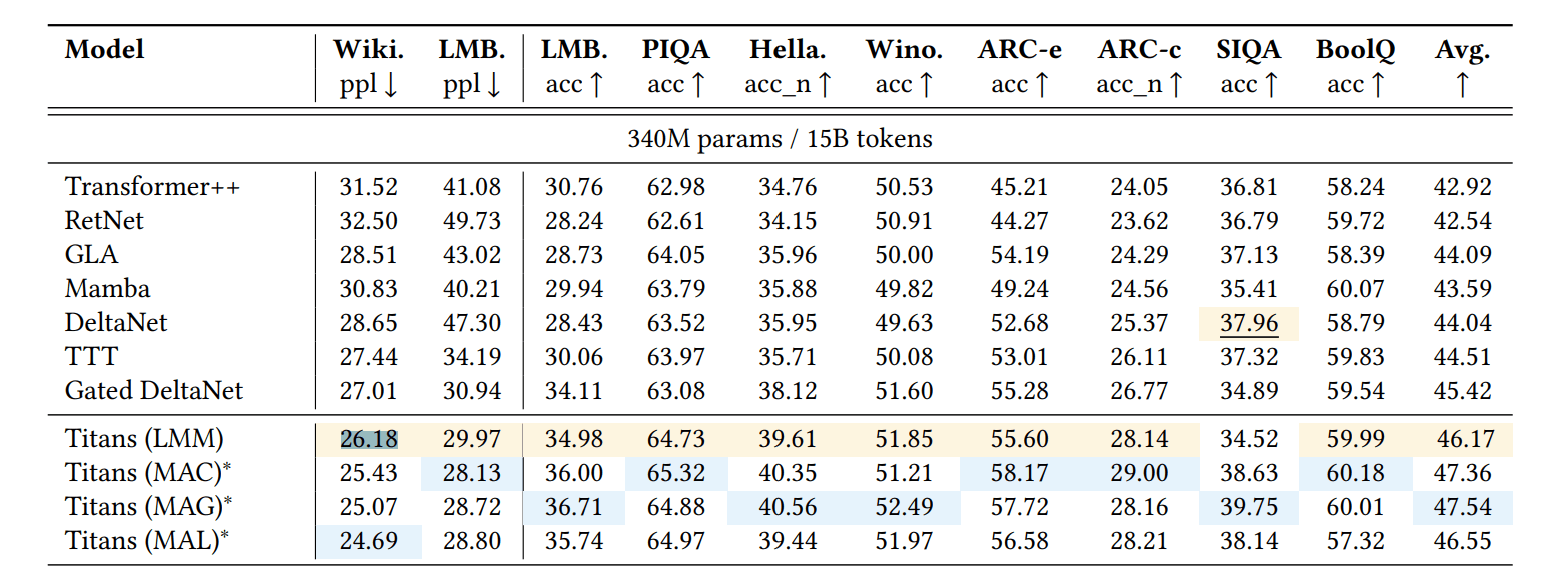
The authors validated Titans’ superiority through experiments, showing it outperforms Transformers and recent recurrent architectures across tasks like language modeling, commonsense reasoning, genomic analysis, and time-series forecasting. In language modeling, Titans achieved a perplexity score of 26.18 on WikiText data, significantly better than the enhanced Transformer++’s 31.52.
In the “needle-in-a-haystack” (NIAH) benchmark—finding specific information in long texts—Titans outperformed even massive models like GPT-4. For a 16K-token input, Titans (using only its Long-term Memory Module) achieved 96.2% accuracy, compared to GPT-4’s 88.4%. Other memory-based models like Mamba2 and DeltaNet scored just 5.4% and 71.4%, respectively, highlighting Titans’ dominance. In genomic analysis, Titans achieved state-of-the-art (SOTA) accuracy of 75.2% on the Enhancer gene activity prediction task, surpassing the previous best Mamba-based model’s 74.6%.
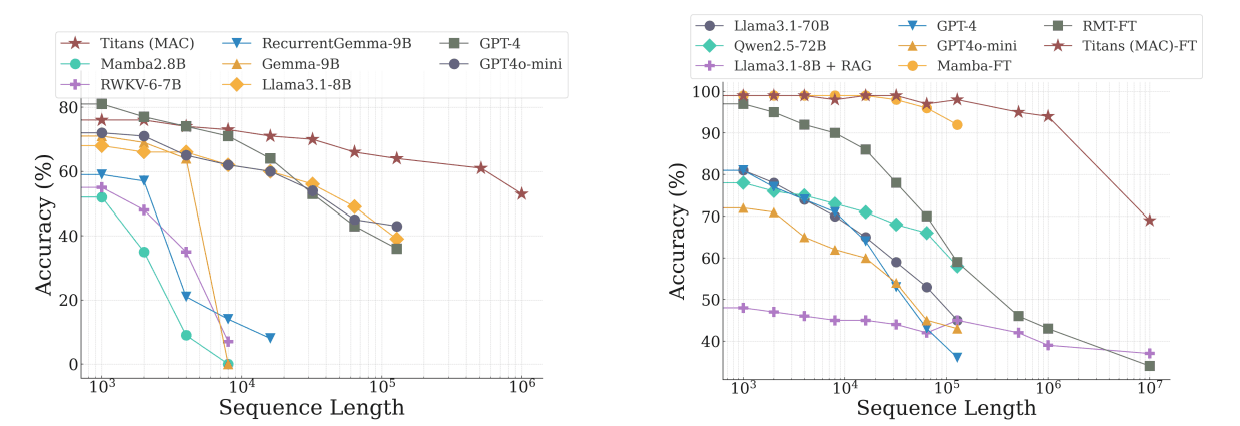
Figure 1 shows Titans maintaining 90–100% accuracy on the challenging BABILong benchmark as sequence lengths scale from \(10^3\) to \(10^7\). In contrast, models like GPT-4 and Llama see sharp accuracy drops with longer sequences, with GPT-4 plummeting above \(10^5\). These results demonstrate Titans’ ability to handle ultra-long-term dependencies that Transformer-based models cannot.
Deep Learning Architecture - Titans’ Potential and Limitations
Just as the Transformer rose to prominence in NLP by modeling sequence dependencies, Titans is poised to conquer fields where Transformers falter—large-scale text, log data, and time-series signal analysis. Imagine a personalized AI assistant: current models forget early conversation details as logs grow, forcing users to re-explain context. A Titans-based model could accumulate millions of words of dialogue, retrieving past context as needed—a critical capability for long-term interactive AI. Titans’ ability to learn during testing aligns with online and continual learning research, bringing us closer to autonomous AI that adapts and improves post-deployment.
However, Titans has challenges. Its increased complexity raises implementation and tuning difficulty, with additional hyperparameters for memory modules requiring careful optimization. Since memory updates during testing, the model’s state changes with each call, posing reproducibility and stability issues. Identical inputs may yield slightly different outputs based on prior data exposure, necessitating management strategies. Security concerns also arise: malicious inputs could corrupt memory, affecting inference. Controlling these test-time learning side effects and ensuring reliability remain future research tasks.

Titans: Pioneering a New AI Paradigm
The history of deep learning is a history of architectural innovation. Titans, an intriguing post-Transformer architecture, combines short-term (attention) and long-term (Neural Memory) mechanisms to transcend memory limits. Its philosophy—efficiently processing long sequences and enabling ongoing learning during operation—charts a new course for AI development. While still experimental and needing validation, its potential impact is undeniable, sparking questions like, “Could Titans be the new Transformer?”
Over the coming years, follow-up research refining Titans’ ideas and real-world applications will unfold. If its concepts mature and performance solidifies, AI could evolve into a truly intelligent companion, understanding vast information and adapting autonomously. Watching Titans shape the next chapter in deep learning’s evolution will be an exciting journey for those in the field.
Start your Free-trial: https://buly.kr/3CO3AAX
Schedule an Meeting: https://abit.ly/6tr1uz