AlphaFold 기반 신약개발 연구 전략


SBDD(Structure-Based Drug Design)
이전 글에서 CADD(Computer-Aided Drug Design)는 크게 SBDD(Structure-Based Drug Design)와 LBDD(Ligand-Based Drug Design)로 나눌 수 있다고 말씀드렸습니다.

SBDD : 장점과 단점
SBDD는 신약 개발의 표적이 되는 단백질의 3차원 구조 정보를 기반으로 진행됩니다. 대표적인 SBDD 과정으로는, 대량의 화합물 라이브러리에서 표적 단백질에 안정적으로 결합하는 분자 구조(유효 물질)를 찾는 virtual screening, 그리고 확보한 유효 물질이 더 잘 결합할 수 있도록 분자 구조를 최적화하는 hit/lead optimization이 있습니다. 약물의 활성이 표적 단백질과의 상호작용 결과라는 점에서, 3차원 공간에서의 binding pocket 형태나 단백질-약물 상호작용을 반영할 수 있는 SBDD는 매우 강력한 도구라 할 수 있습니다.
하지만 이러한 3차원 단백질 구조의 활용은 동시에 SBDD의 가장 큰 약점이 되기도 합니다. SBDD의 핵심은 단백질과 화합물의 3차원 결합 구조를 바탕으로 결합 에너지(즉, 활성)를 예측하는 것인데요. 이를 위해서는 올바른 단백질-화합물 결합 구조를 입력 정보로 사용하는 것이 매우 중요합니다.
문제는 이 결합 구조가 실험적으로 결정된 경우가 거의 없다는 점입니다. 그래서 대부분의 경우, docking을 통해 결합 구조를 예측하는 과정을 거치게 됩니다. 아래 그림은 docking 과정에서 고정된 단백질 구조에 화합물의 입체 구조(conformation)를 다양하게 바꿔가며 단백질-화합물 복합체를 생성하는 모습을 보여줍니다.

SBDD : Docking 과정 및 Scoring Function
Docking 과정에서는 단백질 구조를 고정한 상태에서 화합물의 conformation을 다양하게 바꿔가며 결합 구조를 탐색합니다. 이때 화합물과 단백질 간의 상호작용을 평가해 점수를 부여하는 scoring function이 사용되며, 보통 상위 10개 전후의 결합 구조가 결과로 제공됩니다.
단백질 구조를 고정하는 방식은 계산 효율 면에서는 유리하지만 정확도는 떨어질 수 있습니다. 단백질의 구조는 약물 결합이나 다른 단백질과의 상호작용에 따라 달라질 수 있기 때문이죠. 결국 고정된 단백질 구조를 사용하는 docking에서는, 어떤 구조를 선택할지 신중하게 판단하는 것이 중요합니다.
표적 단백질의 실험 구조가 없는 경우
그렇다면 표적 단백질의 실험 구조가 없는 경우에는 어떻게 해야 할까요? 전통적으로는 homology modeling과 같은 방법을 사용해 단백질 구조를 예측합니다. 다만 이 방법은 일정 수준 이상의 sequence identity(보통 30% 이상)를 가진 단백질의 3차원 구조가 있어야 한다는 한계가 있습니다. 또한 예측된 구조를 더 정밀하게 다듬기 위해, MD simulation 등으로 추가적인 최적화를 진행해야 하는 어려움도 여전히 존재합니다.

AlphaFold의 등장이 시사하는 점
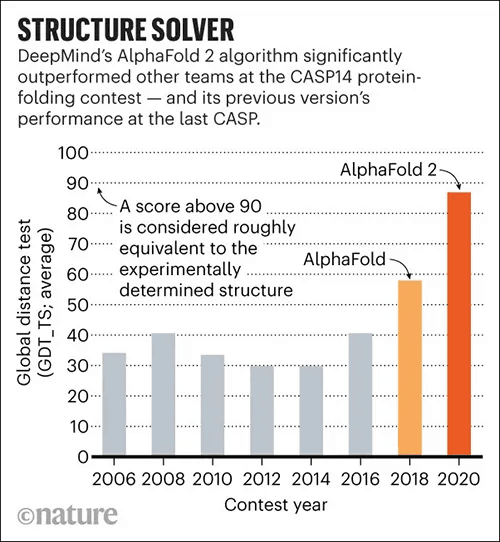
단백질 구조 예측은 오랜 시간 동안 많은 관심을 받아온 분야이며, AlphaFold가 등장하기 전까지는 절대적인 강자가 없는 춘추전국시대와 같았습니다. AlphaFold는 2018년 갑작스럽게 등장해 기존 방법들을 압도했고, 2020년에는 이 분야를 사실상 평정했습니다. 아래 그림을 보면 AlphaFold, 특히 AlphaFold2는 매우 뛰어난 성능을 보이며, GDT(Global Distance Test) 점수가 90에 가까워 예측된 구조가 실험 구조에 매우 근접함을 알 수 있습니다.
AlphaFold 단백질 구조 예측의 한계점
그렇다면 이제 AlphaFold가 예측한 단백질 구조를 사용해서 모든 문제가 해결할 수 있는 걸까요? AlphaFold는 단백질만을 고려해서 구조를 예측하기 때문에, 다음과 같은 3가지 한계가 있습니다.
- 약물이 결합하는 위치인 binding site에 대한 명확한 정보가 없습니다. 그렇다면 AlphaFold 구조는 주로 어떤 상황에서 사용될까요? 주로 데이터 확보가 어려운 first-in-class drug 연구에서 활용될 가능성이 높습니다. 반면, best-in-class 연구의 경우에는 표적 단백질 구조나 활성 데이터가 이미 충분히 축적되어 있기 때문에 굳이 AlphaFold 구조를 사용할 필요는 없습니다. 결국 다른 정보 없이 AlphaFold 구조만으로 binding site를 정의하거나, 핵심 상호작용을 찾는 것은 쉽지 않은 일입니다.
- 단백질은 고정된 형태가 아니라, 끊임 없이 움직이는 유동적인 구조라는 점을 다시 한 번 떠올려볼 필요가 있습니다. 화합물이 단백질에 결합할 경우, 그 구조에 크고 작은 변화를 일으킬 수 있습니다. 하지만 AlphaFold는 단백질만 있는 구조(Apo form)를 예측하기 때문에, 화합물 결합으로 인해 구조 변화가 발생하는 경우에는 AlphaFold 구조가 적절하지 않을 수 있습니다.
- 금속 이온이나 ATP 같은 cofactor가 존재하는 경우에는 어떻게 해야 할까요? 이들이 Binding site와 거리가 있다면 다행이지만, 가까울 경우 약물과 직접 상호작용할 가능성이 있습니다. 이럴 땐 모델링 과정에서 cofactor를 적절한 위치에 배치해주는 작업이 필요합니다.
AlphaFold를 활용한 신약 개발 정보 확보
자, 그럼 이제부터는 AlphaFold 예측 구조만 가지고 있는 상황에서, 신약 개발 연구에 필요한 정보를 어떤 방식으로 확보할 수 있을지 알아보겠습니다. 전체적인 과정은 아래 그림에 정리되어 있습니다.
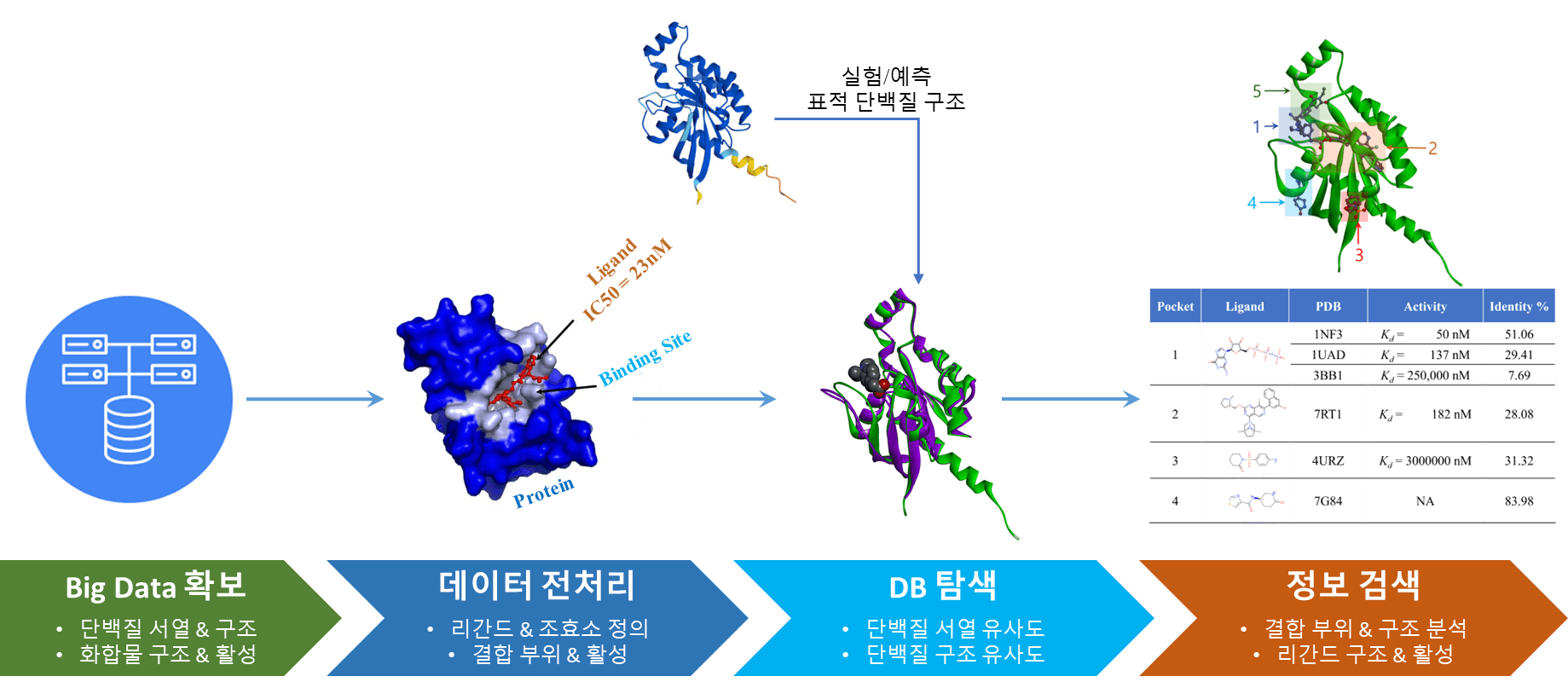
이 과정은 대량의 정보 처리 작업이 필요하기 때문에 수작업으로 진행하기는 어렵습니다. 신약개발 연구자가 쉽게 사용할 수 있도록 자동화하여 하이퍼랩에 추가 할 예정이니 많은 기대 바랍니다! 하이퍼랩에 추가되기 전에 사용이 필요하시다면 연락 주시기 바랍니다.
1. 가장 먼저 표적 단백질의 AlphaFold 구조를 확보하겠습니다. 예제로는 RCSB에 구조 정보가 없는 Epididymis secretory sperm binding protein(UniProt ID: A0A024R0C8)을 표적 단백질로 사용하겠습니다. AlphaFold 웹페이지에서 “Epididymis secretory sperm binding protein”을 검색하면 매우 많은 검색 결과를 확인 할 수 있습니다. 원하는 단백질을 정확하게 검색하기 위해서는 UniProt ID를 사용하는 것을 추천 합니다. UniProt ID는 UniProt 홈페이지에서 확인 할 수 있으며, 여기서는 A0A024R0C8 검색하여 AlphaFold 구조를 다운로드합니다.
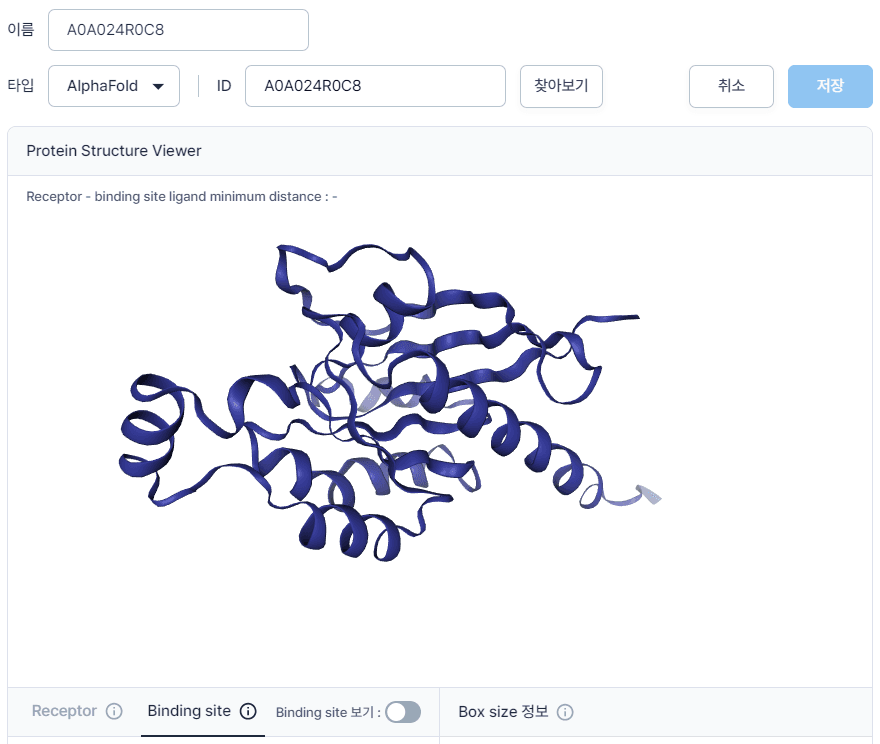
하이퍼랩에서는 “Protein Structure” 탭에서 “타입”을 “AlphaFold”로 선택하고 UniProt code를 입력하시면 손쉽게 단백질 구조를 얻으실 수 있습니다.
참고로 UniProt 정보에 따르면 이 단백질은 GTPase activity가 있고 small GTPase mediated signal transduction에 관여한다고 합니다.

2. 이제 RCSB에서 AlphaFold 예측 구조와 유사한 단백질 구조를 찾아봅시다! 여기서부터는 대량의 데이터를 다루기 때문에, 수작업으로 진행하기는 사실상 불가능합니다. 따라서 과정은 간단히 설명하고, 결과에 집중하도록 하겠습니다.
단백질 구조의 유사도를 확인하기 위해서는 먼저 두 단백질의 서열 및 구조 정렬(sequence & structure alignment)이 필요합니다. 그런 다음, 유사한 정도를 평가하는데요. 이때는 보통 두 단백질의 아미노산(일반적으로 CA 원자) 사이의 RMSD를 계산하거나, TM-score, p-value 등을 사용할 수 있습니다.

이러한 과정을 통해 A0A024R0C8과 유사한 PDB 구조를 약 1,200개 확보하였습니다. 검색된 단백질들은 KRAS, HRAS, Rap1, RHO 등 표적 단백질과 기능적으로, 그리고 구조적으로 유사한 단백질로 확인됩니다.
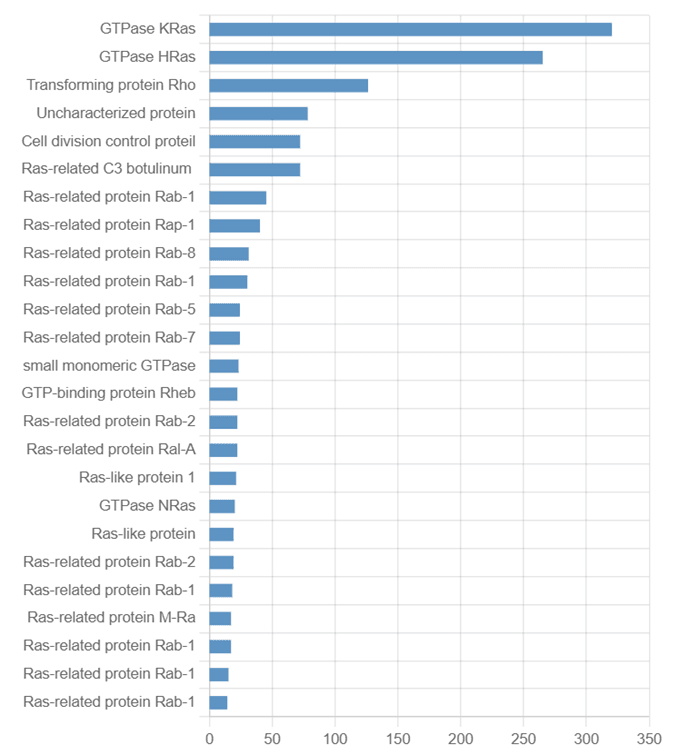
구조 유사성이 높은 단백질 구조들을 확보했다면, 이제 이 구조들에 존재하는 inhibitor 등의 ligand를 정의할 차례입니다. 물론 각 구조를 하나하나 살펴보고 실험 논문을 통해 ligand를 확인하는 것도 가능하겠지만, 현실적으로는 어렵습니다. RCSB에는 20만 개가 넘는 PDB 구조가 저장되어 있기 때문이죠.
대신, PDBBind, BindingDB와 같은 데이터베이스를 활용하는 방법이 있습니다. 이들 DB에는 RCSB PDB 구조에 포함된 ligand들의 활성 데이터가 정리되어 있어, 상당수의 ligand 정보를 자동으로 확인할 수 있습니다.
히츠에서는 최대한의 실험 정보를 수집하여, ligand와 cofactor에 대한 자체 DB를 구축하고 있으며, 이를 기반으로 하이퍼랩에서 binding site를 자동으로 정의하는 기능도 제공하고 있습니다.
데이터 기반 정보 확보 및 분석
이제 유사도가 높은 단백질 구조들과, 이들 구조에 존재하는 활성 분자들의 정보를 확보했습니다. 이제 남은 과정은 이 정보를 AlphaFold 구조에 대입하는 것입니다. 이러한 과정을 통해 binding site로 작용할 가능성이 높은 위치를 예측할 수 있습니다. 아래 그림은 데이터베이스에서 검색된 유사 단백질 구조들과, 각 구조의 binding site 및 ligand 활성 정보를 정리한 것입니다.
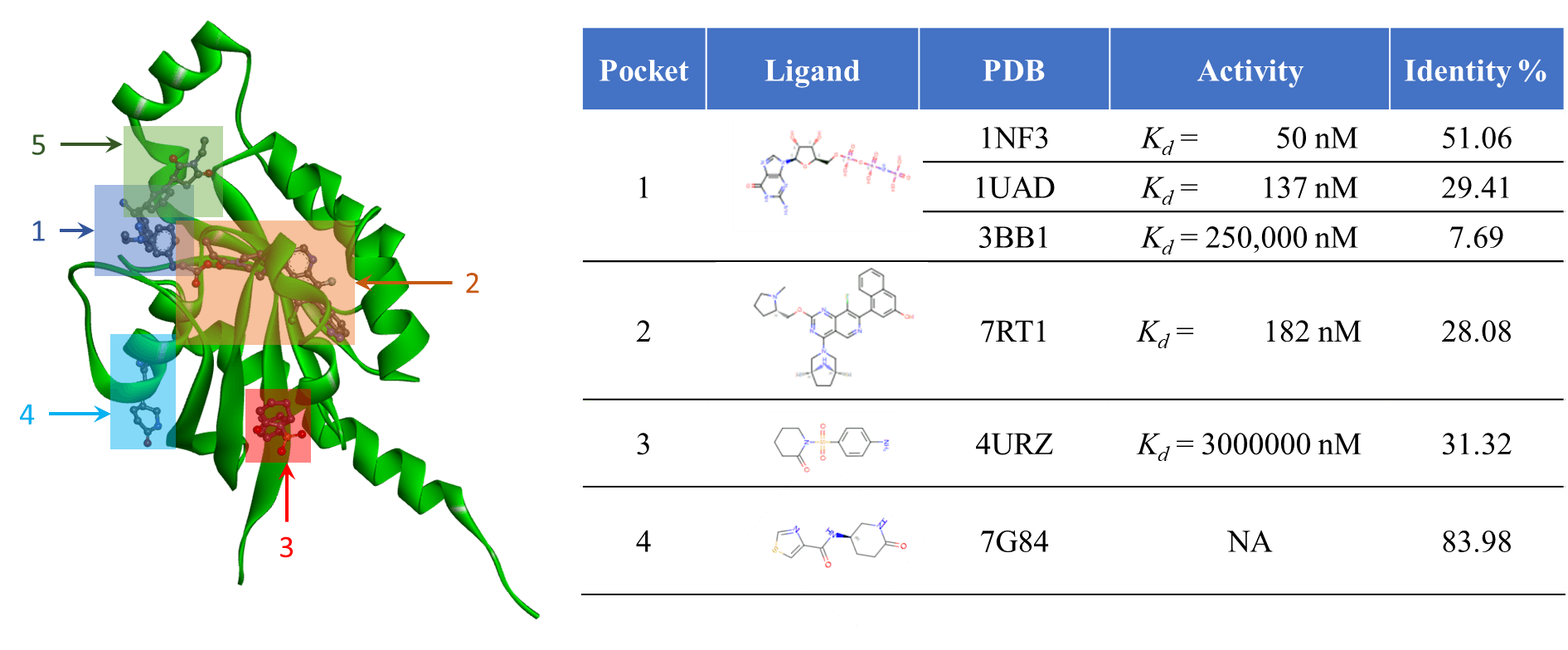
위 그림에서는 binding site일 가능성이 높은 5개의 위치와, 각 site에 대한 근거 데이터를 함께 보여주고 있습니다. 물론 이 정보들을 우리가 관심 있는 단백질에 100% 그대로 적용할 수는 없습니다. 주어진 데이터를 분석해 옥석을 가려내는 과정이 필요합니다.
예를 들어 위 그림에서 1번 site에 결합하는 물질은 1NF3에서는 Kd값이 50nM으로 매우 높은 활성을 보이지만, 3BBI에서는 250,000nM으로 사실상 활성이 없습니다. 같은 분자인데 왜 이렇게 활성이 크게 차이날까요?
이유는 두 단백질의 binding site를 구성하는 잔기(residue)들의 유사성에 있습니다. 잔기 구성이 유사할수록, 한 단백질의 ligand가 다른 단백질에서도 유사한 활성을 보일 가능성이 높다는 것은 직관적으로도 이해할 수 있죠. 실제로 A0A024R0C8에 대해, 1NF3와 3BBI의 sequence identity를 비교해보면 각각 51.06%와 7.69%로 큰 차이가 있다는 것을 알 수 있습니다. 이 차이가 활성의 차이로도 이어진다고 볼 수 있습니다. 아래 그림은 binding site를 구성하는 잔기를 비교한 그림으로, 동일한 잔기는 파란색, 다른 잔기는 빨간색으로 표시됩니다.

1NF3의 경우, A0A024R0C8와 binding pocket을 구성하는 잔기들이 거의 동일하지만, 3BB1은 이와 반대로 매우 다르다는 것을 확인할 수 있습니다. 이 경우에는 당연히 pocket이 유사한 1NF3의 정보를 활용하는 것이 더 적절해 보입니다. 데이터 기반 정보의 확보 및 분석 전략은, 사용하는 데이터베이스의 성격과 목적에 따라 달라질 수 있습니다. 예를 들어, 결합 부위를 구성하는 잔기들의 보존 여부나 구조적 유동성 분석을 바탕으로, AlphaFold 구조를 최적화하는 전략도 고려해볼 수 있습니다.
마무리
SBDD와 단백질 구조 예측 기술인 AlphaFold는 현대 신약 개발 분야에서 중요한 도구로 자리 잡고 있습니다. 하지만 이러한 기술들은 여전히 한계를 갖고 있으며, 완벽한 해결책이라기보다는 연구와 개발 과정에서 실질적인 도움을 주는 도구로 활용되고 있습니다. 앞으로의 신약 개발에서는 SBDD와 AlphaFold를 비롯한 다양한 기술들을 유기적으로 결합하여, 새로운 치료제의 발견과 개발에 더욱 기여할 수 있기를 기대합니다.