초대형 화합물 라이브러리(Ultra-large Library)의 혁신과 미래


초대형 화합물 라이브러리의 등장과 중요성
Ultra-large library(이하 virtual library)는 신약 개발 과정에서 사용되는 대규모 화합물 데이터베이스로, 일반적으로 수억에서 수천억 개의 화합물을 포함하는 거대한 규모의 라이브러리를 의미합니다. 전통적인 화합물 라이브러리가 수천에서 수만 개의 화합물만을 다루었던 것과 비교하면, 이는 혁신적인 발전이라 할 수 있습니다.
특히 DNA-encoded Library(DEL) 기술의 발전과 AI를 활용한 컴퓨터 가상 스크리닝 기술의 혁신으로 인해 가능해진 이 초대형 라이브러리는, 실제 합성 가능한 화합물부터 가상의 화합물까지 광범위한 화학 구조를 포함하고 있습니다. 이러한 방대한 규모는 신약 개발자들에게 이전에는 상상할 수 없었던 수준의 화학적 다양성과 가능성을 제공하며, 특히 인공지능과 결합하여 새로운 구조의 약물 후보 물질을 효율적으로 발견할 수 있는 기회를 제공합니다.
Virtual Library의 원리와 활용
Virtual library는 building block과 reaction template의 조합으로 만들어집니다. Building block은 상대적으로 저렴하고 안정적이며, 다양한 반응기를 가진 작은 분자들이고, reaction template들은 반응 조건이 단순하고 수율이 높은 반응들입니다. 예를 들어, 10,000개의 building block과 10개의 reaction set이 있다면, 최대 10,000 × 10,000 × 10 = 10¹¹개의 가상 분자를 만들 수 있습니다. 물론 일부 반응은 일부 building block 쌍에 적용하기 어렵기 때문에 실제 숫자는 이보다 적겠지만, 이를 고려하더라도 엄청나게 많은 분자 수입니다.
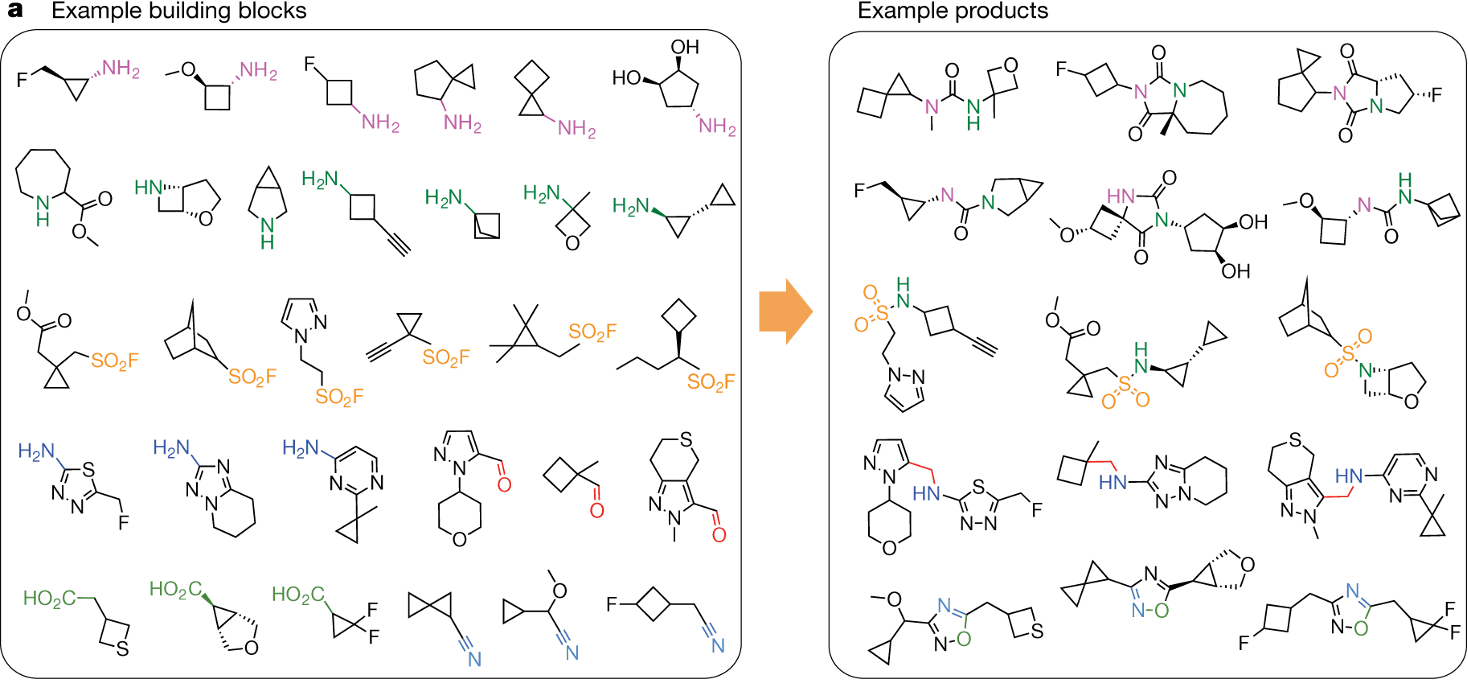
이는 기존 고효율 스크리닝(High-throughput screening, HTS)이 가진 약 백만 개 수준의 화합물 수 한계를 극복하고, 신약 개발의 성공 가능성을 획기적으로 높일 수 있는 혁신적인 도구로 평가받고 있습니다.
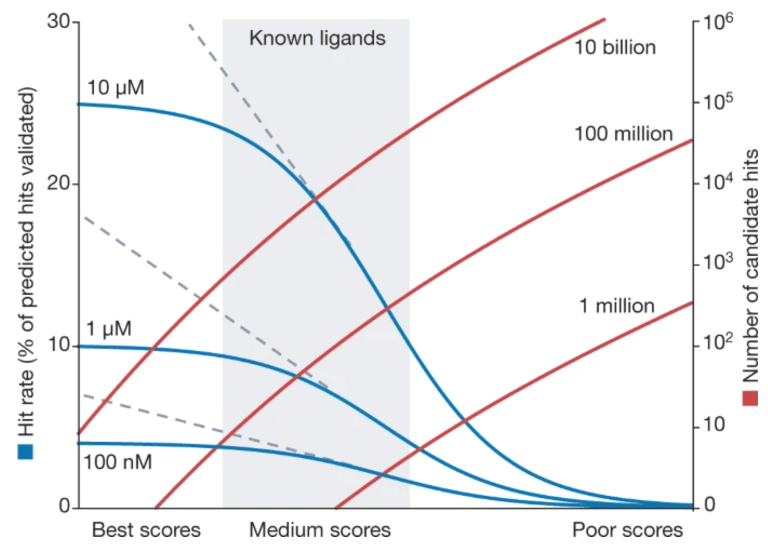
Virtual library의 가장 큰 장점 중 하나는 hit rate를 높일 수 있다는 점입니다. 동일한 스크리닝 방법을 사용하더라도, 라이브러리 크기를 늘림으로써 hit rate가 증가합니다.
직관적으로 이해해 보자면, 한 반(학생 수 십여 명)에서 시험 1등보다는 한 학교(학생 수 백여 명)의 1등이 공부를 잘할 확률이 높은 것과 같은 이치입니다.
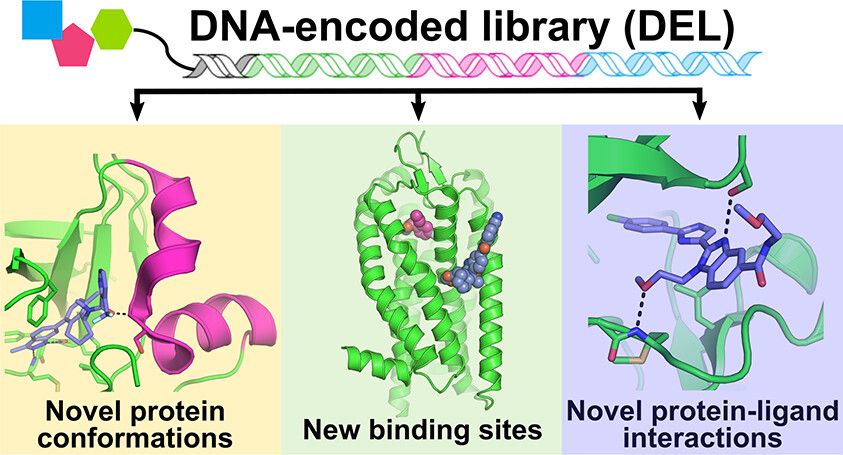
DNA-encoded Library(DEL)의 혁신과 활용
DNA-encoded Library(DEL) 기술의 혁신은 초대형 라이브러리 구축의 핵심 기술로 자리 잡았습니다. 각각의 화합물에 고유한 DNA 바코드를 부착하는 이 기술은 수천억 개의 화합물을 동시에 합성하고 스크리닝할 수 있게 만들었습니다. X-Chem사의 경우, 2,000억 개 이상의 화합물을 포함하는 DEL 라이브러리를 구축했으며, 이는 지속적으로 확장되고 있습니다. 최근 연구에 따르면, DEL 기술을 통해 발견된 히트 화합물들은 기존 방법으로는 찾기 어려웠던 독특한 결합 모드를 보여주며, 신약 개발의 새로운 가능성을 제시하고 있습니다.
(참고: https://pubs.acs.org/doi/10.1021/acs.jmedchem.3c01861).
화학 공간의 혁신적 탐색
최근 연구들은 초대형 라이브러리가 단순히 화합물의 수만 많은 것이 아니라, 화학 공간의 더 넓은 영역을 효과적으로 탐색할 수 있게 해준다는 것을 보여주고 있습니다.
특히 다양성 지향적 합성(Diversity-oriented synthesis, DOS) 기술과 DEL의 결합은 기존 상업용 스크리닝 라이브러리에서는 찾아볼 수 없었던 새로운 특성을 가진 분자들의 합성을 가능하게 했습니다.
실제로 한 연구팀은 370만 개의 구조적으로 다양한 화합물을 포함하는 DEL을 구축하여 학술 연구 커뮤니티에 공개했으며, 이는 초기 신약 개발 단계를 가속화하는 데 크게 기여하고 있습니다.
(참고: https://pubmed.ncbi.nlm.nih.gov/37582753).
머신러닝과 AI 기반 스크리닝의 도약
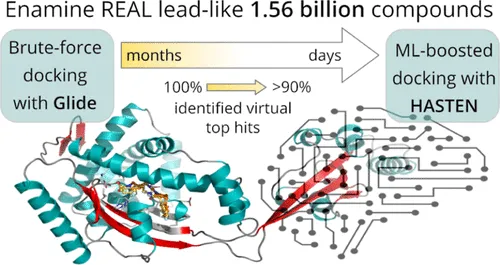
머신러닝 기술의 발전은 초대형 라이브러리 활용을 한 단계 더 끌어올렸습니다. 최근 연구들은 리간드 기반(LB)과 구조 기반(SB) 접근법을 통합하여 다양한 측면에서 단백질-리간드 상호작용을 예측하는 데 성공했습니다. 특히 이러한 AI 기반 기술은 수십억 개의 화합물을 단 몇 분 또는 몇 시간 만에 스크리닝할 수 있게 만들었으며, 거짓 양성(false positive) 결과를 최소화하는 데도 큰 도움을 주고 있습니다.
(참고: https://pubmed.ncbi.nlm.nih.gov/38129992).
예를 들어, HASTEN이라는 도구는 ML 예측과 도킹 시뮬레이션을 결합하여 스크리닝 처리량을 크게 향상시켰습니다. 실제 사례 연구에서는 전체 라이브러리의 단 1%만을 도킹하더라도, 상위 1,000개의 가상 히트 중 90%를 식별할 수 있었다고 보고되었습니다.
(https://pubs.acs.org/doi/10.1021/acs.jcim.3c01239).
Virtual library는 이온 채널을 표적으로 하는 물질 발굴에서 좋은 유효 물질을 발굴하였습니다. 당뇨병, 간질, 고혈압, 암, 만성 통증 등 다양한 질환의 치료제 개발에서 획기적인 결과를 도출하고 있으며, 특히 컴퓨터 하드웨어와 소프트웨어의 발전으로 인해 더욱 효과적인 스크리닝이 가능해졌습니다.
(참고: https://www.frontiersin.org/journals/molecular-neuroscience/articles/10.3389/fnmol.2023.1336004/full).
SARS-CoV-2 메인 프로테아제(M<sup>pro</sup>) 저해제 개발에서도 초대형 라이브러리 스크리닝이 중요한 역할을 했습니다. AI 기반 스크리닝 방법을 통해 수십억 개 화합물 중 효과적인 저해제를 발견하는 데 성공했으며, 이는 인공지능 기술과 초대형 라이브러리의 시너지 효과를 잘 보여주는 사례입니다.
(참고: https://www.tandfonline.com/doi/full/10.1080/17460441.2023.2171984).
초대형 라이브러리의 과제와 전망
초대형 라이브러리 기술은 지속적으로 발전하고 있으며, 특히 인공지능 기술과의 결합을 통해 더욱 강력한 도구로 진화하고 있습니다. 그러나 여전히 해결해야 할 과제들이 남아 있습니다. 특히 더 도전적인 표적들을 다루기 위한 방법론의 개발이 필요하며, 화학 공간의 적절한 선택과 활용 방안에 대한 연구가 계속되어야 합니다. 이러한 과제들이 해결된다면, 초대형 라이브러리는 신약 개발의 성공률을 획기적으로 높이는 핵심 기술로 자리 잡을 것으로 기대됩니다.
이러한 발전과 도전은 신약 개발 분야에 새로운 패러다임을 제시하고 있으며, 앞으로도 계속해서 혁신적인 발전이 이루어질 것으로 예상됩니다. 특히 인공지능 기술의 발전과 함께, 초대형 라이브러리의 활용은 더욱 효율적이고 정확해질 것으로 기대됩니다.